OpenClaw 技术架构深度解析

先分享个我一直在用的几个机场
1. 稳定速度快, 一般我买24块钱/年,一个月有128G/流量,足够随便刷外网(不适合编程,适合看视频、网页、图片)
机场地址:https://kitty.sb/#/register?code=BOYYIwAG
2. 如果需要干净点的梯子,用这个0.6刀/月,特别是针对google的gemini:
机场地址:https://mitce.net/aff.php?aff=29135
3. 再好一点的梯子用这个,我编程主梯子,40元/200G(性价比高的 90元800G),或者15~25元/月,有纯家宽的(三倍速率),非常干净,适合antigravity/claude/chatgpt:
https://dc.vv11.cloud/#/register?code=EbtcWOB0 新用户9折优惠码:new90
引言
最近每个人都在谈论 OpenClaw,但它究竟是如何工作的呢?
作者深入研究了 OpenClaw(原名 Moltbot(原名 ClawdBot))的架构,包括它如何处理智能体执行(agent executions)、工具调用(tool use)、浏览器等功能。对于 AI 工程师来说,这里面有很多值得学习的经验。
了解 OpenClaw 的底层工作原理,能让我们更好地理解这个系统及其能力,最重要的是,明白它擅长什么、不擅长什么。
这一切始于作者个人对 OpenClaw 如何处理记忆(memory)以及其可靠性的好奇。
在这篇文章中,作者将从表层介绍 OpenClaw 的工作原理。
OpenClaw 的技术本质
大家都知道 OpenClaw 是一个可以在本地运行或通过模型 API 使用的个人助手,你甚至可以在手机上轻松访问它。但它的技术本质是什么?
从核心来看,OpenClaw 是一个 TypeScript 写的 CLI 应用程序。
它不是 Python 项目,不是 Next.js,也不是 Web App。
它是一个进程(process),能够:
在你的机器上运行,并暴露一个 Gateway Server(网关服务器)来处理所有渠道连接(Telegram、WhatsApp、Slack 等)
调用各类 LLM API(Anthropic、OpenAI、本地模型等)
在本地执行工具(tools)
按你的需求在电脑上做事情
架构总览
为了更直观,下面用一个例子解释:你在聊天软件里给 OpenClaw 发消息,一直到你收到回复,中间发生了什么。
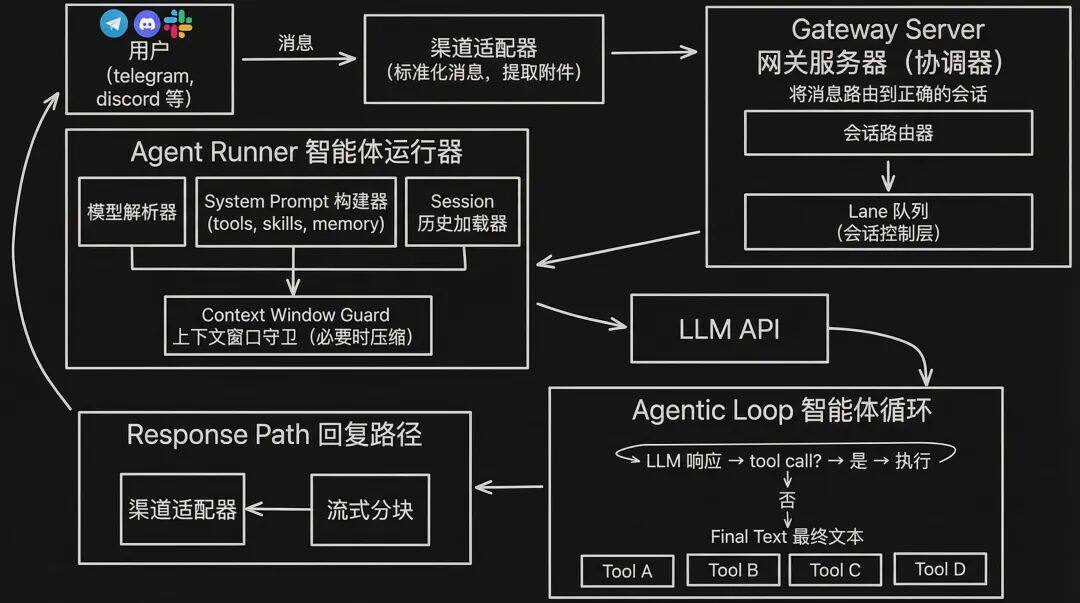
当你在消息应用中向 OpenClaw 发送提示时,会发生以下过程:
1. 渠道适配器(Channel Adapter)
渠道适配器接收你的消息并进行处理(标准化、提取附件)。不同的消息应用和输入流有各自专用的适配器。
2. 网关服务器(Gateway Server)
网关服务器是任务/会话协调器(task/session coordinator),它接收你的消息并将其传递给正确的会话。这是 OpenClaw 的核心。它处理多个重叠的请求。
为了让操作串行化(serialization),OpenClaw 使用基于 lane 的命令队列(lane-based command queue)。一个会话有自己专用的 lane,低风险的可并行化(parallelizable)任务可以在并行 lane 上运行(例如 cron 定时任务)。
这与常见的 async/await 乱麻式写法(“async/await spaghetti”)相对。过度并行会降低可靠性,并带来大量调试噩梦。如果你做过智能体系统,多半也体会过这一点。
这也是 Cognition 那篇博文《不要构建多代理系统》的洞见。
简单地为每个 agent 搞一套 async 并发,日志会变成一坨交错的垃圾,几乎不可读;如果它们共享状态(shared states),竞态条件(race conditions)会变成你开发中必须时刻担心的风险。
Lane 是对队列(queue)的抽象:默认就是“串行化架构”,而不是事后补丁。作为开发者,你手写业务逻辑,队列系统帮你处理竞态。
你的心智模型会从:
“我需要加什么锁?”(what do I need to lock?)
变成:
“哪些东西是安全可并行的?”(what‘s safe to parallelize?)
3. 智能体运行器(Agent Runner)
这是真正“AI”介入的地方。它会:
判断用哪个模型
选择可用的 API Key(如果某个 key 不可用,就把该配置标记为 cooldown 并尝试下一个)
如果主模型失败,会回退到其他模型(fallback)
Agent Runner 会动态拼装 system prompt:包含可用工具(tools)、技能(skills)、记忆(memory),然后追加 session 历史(从 .jsonl 文件读取)。
接着会交给 Context Window Guard(上下文窗口守卫):检查上下文窗口是否还有足够空间。如果上下文快满了,要么压缩整理 session(对上下文做摘要),要么优雅失败(fail gracefully)。
4. LLM API Call(大模型 API 调用)
LLM 调用本身是流式输出(streaming responses),并对不同供应商(providers)做了统一抽象。如果模型支持,还可以请求 extended thinking(扩展思考)。
5. 智能体循环(Agentic Loop)
如果 LLM 返回的是工具调用(tool call)响应,OpenClaw 就会在本地执行工具,并把结果追加回对话。
这个过程会重复,直到:
LLM 输出最终文本(final text),或
达到最大轮数(max turns,默认约 20)
“魔法”也发生在这里:包括后面会提到的 Computer Use(让智能体操作你的电脑)。
6. 回复路径(Response Path)
比较常规:回复通过渠道回到你那边。
同时,session 会持久化到一个基础的 JSONL(JSON Lines) 文件:每行是一个 JSON 对象,记录用户消息、工具调用、工具结果、模型回复等。这就是 OpenClaw 的“记住”(基于 session 的记忆)方式。
这涵盖了基本架构。现在让我们深入一些更关键的组件。
OpenClaw 如何“记忆”
没有靠谱的记忆系统,AI 助理就跟金鱼一样(转头就忘)。
OpenClaw 用两套机制:
上面提到的 JSONL 会话转录(session transcripts)
记忆文件(memory files):Markdown 格式,存放在 MEMORY[.]md 或 memory/ 目录
检索时,它用的是 向量检索(vector search)+ 关键词匹配(keyword matches) 的混合方案(hybrid),同时吃到两边的优势。
比如搜 “authentication bug”,既能找到提到 “auth issues” 的文档(语义匹配/semantic),也能命中精确短语(关键词匹配)。
向量检索用 SQLite
关键词检索用 FTS5(SQLite 的全文检索扩展)
embedding(向量嵌入)的提供方可配置(embedding provider is configurable)
它还利用 Smart Syncing(智能同步):当文件监视器(file watcher)检测到文件变更时触发同步。
这些 Markdown 记忆文件是 agent 自己通过标准的“写文件(write file)”工具生成的:没有专门的 memory-write API,就是直接写到 memory/*.md。
当开启一段新对话时,会有一个 hook(钩子) 抓取上一段对话,并写一份 Markdown 摘要。
整体上,OpenClaw 的记忆系统非常简单,和很多“工作流记忆(workflow memories)”实现很像:没有记忆合并(merging of memories),也没有按月/周做记忆压缩(memory compressions)。
这种简单可能是优势也可能是坑:作者个人更偏好“可解释的简单”,而不是复杂的意大利面式系统(spaghetti)。
它的记忆会一直存在,旧记忆与新记忆权重基本相同——也就是说没有遗忘曲线(forgetting curve)。
OpenClaw 的“爪子”:如何使用你的电脑(Computer Use)
这是 OpenClaw 的一个核心“护城河(MOAT)”:你给它一台电脑,它就能用。
它会在你自担风险的前提下给 agent 很大的电脑访问权限,并通过 exec 工具执行 shell 命令,执行环境包括:
sandbox:默认,在 Docker 容器里运行命令
直接在宿主机(host machine)运行
在远程设备(remote devices)上运行
除此之外还有:
文件系统工具(Filesystem tools):read / write / edit
浏览器工具(Browser tool):基于 Playwright,并提供 语义快照(semantic snapshots)
进程管理(Process management / process tool):运行后台长任务、kill 进程等
安全性(可以说:几乎没有?)
类似 Claude Code,OpenClaw 有一个命令 allowlist(允许列表) 机制:用户可以选择“允许一次 / 永久允许 / 拒绝”,并弹窗提示用户确认。
配置示例:
// ~/.clawdbot/exec-approvals.json
{
"agents": {
"main": {
"allowlist": [
{ "pattern": "/usr/bin/npm", "lastUsedAt": 1706644800 },
{ "pattern": "/opt/homebrew/bin/git", "lastUsedAt": 1706644900 }
]
}
}
} 一些安全命令(如 jq, grep, cut, sort, uniq, head, tail, tr, wc)默认就预批准(pre-approved)。
一些危险的 shell 构造默认会被拦截(blocked)。例如下面这些会在执行前就被拒绝:
npm install $(cat /etc/passwd) # command substitution(命令替换)
cat file > /etc/hosts # redirection(重定向)
rm -rf / || echo "failed" # chained with ||(逻辑或链式执行)
(sudo rm -rf /) # subshell(子 shell) 总体安全思路和 Claude Code 很像:在用户允许的范围内给尽可能多的自主性(autonomy)。
浏览器:语义快照(Semantic Snapshots)
OpenClaw 的浏览器工具并不主要依赖截图(screenshots),而是用语义快照:对页面 可访问性树(accessibility tree, ARIA) 的文本化表示。
所以 agent 看到的可能是类似这样的结构:
- button "Sign In" [ref=1]
- textbox "Email" [ref=2]
- textbox "Password" [ref=3]
- link "Forgot password?" [ref=4]
- heading "Welcome back"
- list
- listitem "Dashboard"
- listitem "Settings" 这种做法有几个显著优势:浏览网页并不一定是视觉任务。
一张截图可能有 5MB,而语义快照可能不到 50KB,而且图像 token 成本远高于文本——语义快照的 token 成本只是图像的一小部分。