一文看懂什么是语音VAD(声音活动检测)

还记不记得小时候上课,老师在讲台上滔滔不绝,你和同桌在下面讲悄悄话。突然,老师停顿了下来,教室里一片寂静,这时候你们的说话声就显得格外清晰。老师能立刻分辨出什么时候是她在讲课,什么时候是背景噪音,什么时候是学生在说话。
在语音技术的世界里,也有一位这样时刻在分辨“有效声音”的“纪律委员”,它的名字就是VAD(Voice Activity Detection,声音活动检测)。
一、什么是语音VAD检测?
VAD,顾名思义,它的核心任务只有一个:判断一段音频中,究竟是有人在说话,还是只是环境噪音或一片寂静。
它就像一个极其灵敏的开关,当检测到人的声音时,它就打开(输出“有语音”);当人声停止,只剩下环境音或安静时,它就关闭(输出“无语音”)。它不对语音内容做任何分析,不关心你说的是“你好”还是“再见”,只关心“你是否在说话”。
在语音交互流程中,VAD检测处在人机对话的内容检测步骤:
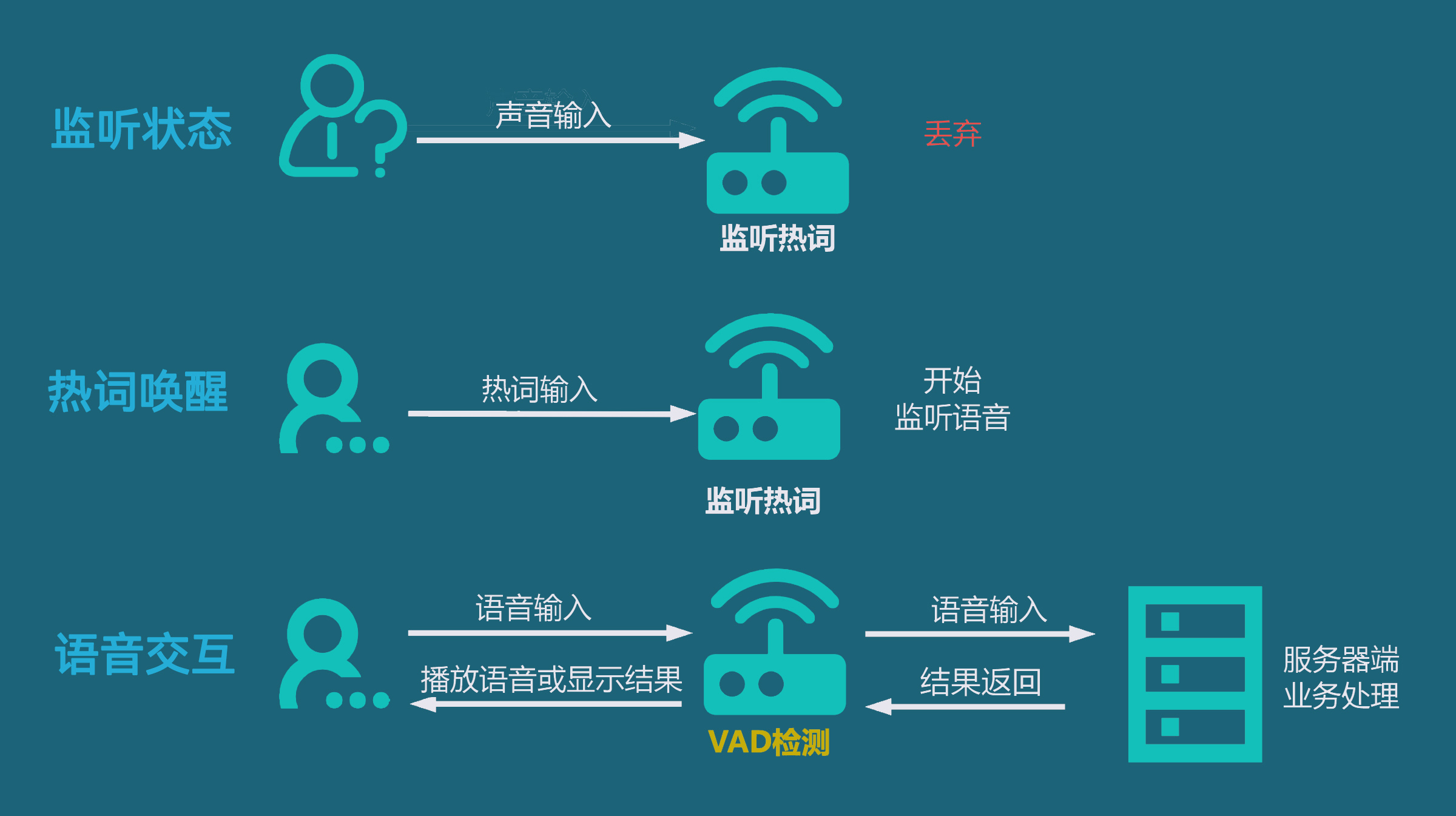
VAD与热词唤醒的关键区别:
热词唤醒 是一个“侦探”,它在茫茫人海中只为寻找那个叫“小明”的特定目标(什么是热词唤醒?为什么用小明举例?可以看这一文《一文看懂什么是语音热词唤醒》,讲解热词唤醒的定义、价值、原理和应用场景)。
VAD 是一个“门卫”,它不关心来访者是谁,只负责判断“是否有人来了”。
二、为什么需要VAD检测?
假设一下,如果一个会议秘书不仅记录了所有人的发言,还把翻书声、咳嗽声、椅子挪动声、以及大段大段的沉默全部一字不差地写下来,这份会议纪要将会多么冗长和混乱。VAD的存在,就是为了避免机器犯这种错误。
总地来说,VAD技术主要有以下三大作用:
节省计算资源,降低系统压力: 语音识别(ASR)是一个非常消耗计算资源的任务。如果没有VAD,机器就需要7x24小时地分析处理麦克风收到的所有声音,包括空调的嗡嗡声、窗外的风声等。这无疑是巨大的浪费。VAD作为第一道关卡,将无效的音频片段直接过滤,只把真正的语音片段交给后续的“CPU大哥”去处理。
节省存储空间和网络带宽: 在录音或实时通话(如微信语音、网络会议)场景中,沉默片段占据了大量时间。VAD可以智能地“掐掉”这些沉默,只记录和传输有语音的部分。这使得录音文件更小,实时通话也更流畅,尤其是在网络不佳的环境下。
提升后续语音任务的准确率: 语音识别模型如果“吃”进去的音频包含了大量的噪音和静音,它的识别准确率会大打折扣。VAD通过提供“干净”的、只包含人声的音频片段,极大地提升了语音转文字、声纹识别等后续任务的效果。
三、VAD技术的原理
VAD的核心挑战在于:如何在复杂多变的环境噪音中,准确地把人声“揪”出来。比如,如何在嘈杂的餐厅里分辨出人声和盘子碰撞声?如何在车里分辨出人声和引擎声?

整个技术流程可以分解为以下几个关键步骤:
第1步:声音的采集与预处理 (Audio Acquisition & Pre-processing) 这一步与热词唤醒完全相同,是所有语音技术的基础。通过麦克风阵列拾音,并进行降噪、回声消除、去混响等操作,获得相对纯净的音频信号。
第2步:声学特征提取 (Feature Extraction) 为了让机器能够“理解”声音,我们需要将声波转换成一组组的数字特征。除了热词唤醒中提到的MFCC,VAD还经常使用一些更简洁、更针对性的特征:
短时能量 (Short-Term Energy): 通常说话时声音的能量会比环境噪音大。
过零率 (Zero-Crossing Rate): 语音信号的波形比很多噪音变化更频繁,过零率可以反映这个特性。
谱熵 (Spectral Entropy): 语音信号的频谱通常更规整有序,而噪音的频谱则更混乱。
音调频率 (Pitch): 人声具有基频和泛音结构,这是区别于很多噪音的显著特征。
第3步:语音活动分析与检测 (Activity Analysis & Detection) 这是VAD技术的核心。系统会分析提取出的特征,来判断当前是否为语音活动。实现方式主要分为三代:
传统方法(基于阈值): 最简单的方式,比如设置一个能量门限,高于它就认为是语音。这种方法简单快速,但在复杂噪音环境下极易出错(例如,一声关门声可能会被误判为语音)。
统计模型方法: 采用更复杂的数学模型(如高斯混合模型GMM),分别对语音和噪音的特征分布进行建模。通过计算当前音频特征更符合哪个模型,来做出判断,准确率大大提升。
深度学习方法: 这是目前的主流。通过使用深度神经网络(DNN/RNN等)对海量的、已标注好的“语音”和“非语音”数据进行学习,让模型自己掌握区分语音和噪音的复杂规律。这种方法鲁棒性最强,即使在极低信噪比的环境下也能取得很好的效果。
第4-步:平滑处理与决策 (Smoothing & Decision) 模型的原始输出可能是断断续续的(例如,一句话中间极短的停顿可能被误判为“无语音”)。为了使检测结果更自然、更符合人的听感,系统会进行平滑处理。
例如设置一个“挂起”机制: 当检测到语音结束后,并不会立即切断,而是会多等待几百毫秒,以防是话语间的短暂停顿,从而将一整句完整地送出。最终,VAD输出的是精确的语音起点(Start)和终点(End)时间戳。
四、VAD的应用场景
VAD作为语音处理链条中“承上启下”的关键一环,应用极为广泛:
语音识别(ASR)的前端处理: 这是VAD最核心的应用。在进行语音转文字前,先用VAD切分出有效的语音片段,是所有语音识别系统的标配。
语音交互系统: 在热词唤醒设备后,VAD立刻开始工作,判断用户指令的开始和结束,从而截取完整的命令送去理解。可以说,热词唤醒负责“打招呼”,VAD负责“听你把话说完”。
实时通信(RTC)与网络电话(VoIP): 在微信、Zoom、Teams等应用中,VAD用于检测你是否在说话。当你沉默时,系统可以不传输数据(该技术称为DTX, Discontinuous Transmission),从而大幅节省带宽,保证通话流畅。
智能录音与会议纪要: 自动跳过会议中的沉默和噪音时段,生成的录音文件更紧凑,后期转写和整理的效率也更高。
五、总结
如果说热词唤醒是开启智能设备大门的“钥匙”,那么VAD就是一位尽职尽责的“速记员”,它确保了我们说的每一句有效的话都能被准确地记录下来,同时又聪明地忽略了所有的无关干扰。它虽然“默默无闻”,却是构建起整个智能语音大厦不可或-缺的基石。