一文看懂什么是语音热词唤醒(Wake-up Word / Hotword Detection)

还记不记得小时候,你在外面玩,玩着玩着就忘记时间了,然后突然空中飘来一句:
小明,快回家吃饭啦!!!

这时候,作为小明的你,是不是马上就意识到你妈喊你吃饭了,停下玩耍,赶回去吃饭。
在语音交互场景中,这里的”小明“就是热词,而你是被”小明“这个名字训练很多次的具有一定权重的算法,一旦听到”小明“这个词,就会意识到这是在叫你。
一、什么是热词唤醒
在语音识别系统中,热词(Hot Words)是指用户期望系统能够优先识别并响应的特定词汇或短语。这些热词通常与用户的应用场景紧密相关,例如智能家居中的“打开灯光”、“播放音乐”,或者车载系统中的“导航到”、“拨打电话”。通过引入热词技术,可以显著提升语音识别的准确性和用户体验。一旦检测到这个预设的唤醒词,设备就会被“唤醒”,并启动完整的语音识别系统,准备接收并执行用户的后续指令。
一些常见的例子:
对您的手机说:“你好,小爱” 或 “Hey Siri”
对智能音箱说:“天猫精灵” 或 “小度小度”
在汽车里说:“你好,奔驰”
这些加粗的短语就是“唤醒词”或“热词”。
二、为什么需要热词唤醒
想象一下,你在玩耍,别人在跟你说话,你肯定听不进去在说什么。但是,如果对方喊你一下名字,再跟你说话,你可能就会集中注意力听对方说话,热词就是为了唤醒你的听觉。
语音交互的应用场景中,作为机器设备,不方便一直处理自然界的声音输入,这会系统的压力很大,体验也不太好,通常语音交互的流程如下图所示:
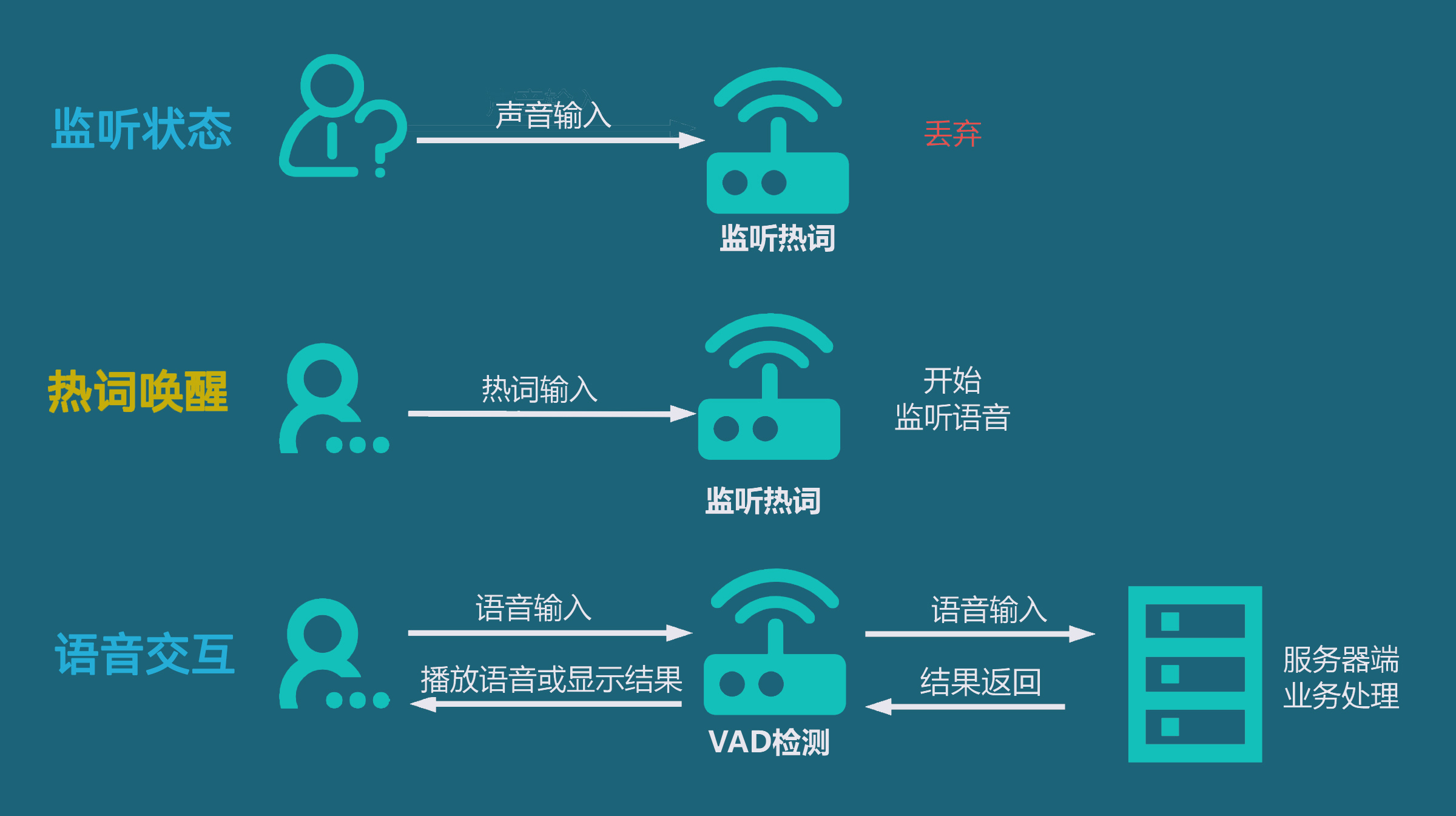
阶段一:监听热词状态
因为大部分时间我们可能不是都在和设备进行语音交互,设备又不能停止工作,但又没必要一直处理外界输入的语音到服务端去处理,但是设备不知道我们什么时候会和它交互,不能关闭语音,这时候由低功耗的热词监听状态一直持续动行着。
阶段二:热词唤醒
在需要和设备进行语音交互前,我们喊一下对应的关键词,这时候设备监听到关键词,理解需要进行语音交互了,就进入工作状态,进行VAD检测(什么是VAD检测,请看另一篇文章《一文看懂什么是语音VAD检测》)。
阶段三:语音交互
热词“激活”系统后,这时候你跟设备对话,输入语音,就能正常由设备处理或者传入到服务器端进行复杂的业务处理(如AI大模型推理,进行你要做的业务功能处理等)
总地来说,热词唤醒有以下作用:
便捷性和即时响应: 用户无需任何物理接触(如按键、触摸屏幕),即可在任何时候(例如在做饭、开车或房间的另一头)与设备进行交互。这大大提升了用户体验,实现了真正的“解放双手”。
节能和高效: 语音唤醒技术通常由一个功耗极低的专用芯片或算法来执行。设备在休眠时,只有这个微小的“耳朵”在工作,而不是整个高性能的处理器。这极大地节省了电量,保证了设备的续航能力。只有在听到唤醒词后,系统才会调动更多资源来处理复杂的语音指令。
开启人机交互的新入口: 它是语音交互的第一步。没有唤醒词,设备就无法知道用户何时在对它说话,也就无法开启后续的智能问答、设备控制等功能。
三、热词技术的原理
热词唤醒(语音唤醒)的技术原理相当精妙,它本质上是一个在 极低功耗 下运行的、高度专注的 关键词识别任务。这个技术领域在学术上通常被称为 关键词识别 (Keyword Spotting, KWS)。
其核心挑战在于:如何在不消耗太多电量的情况下,7x24小时不间-断地、且准确地从周围所有声音中“捕获”到那一个特定的唤醒词。
整个技术流程可以分解为以下几个关键步骤:
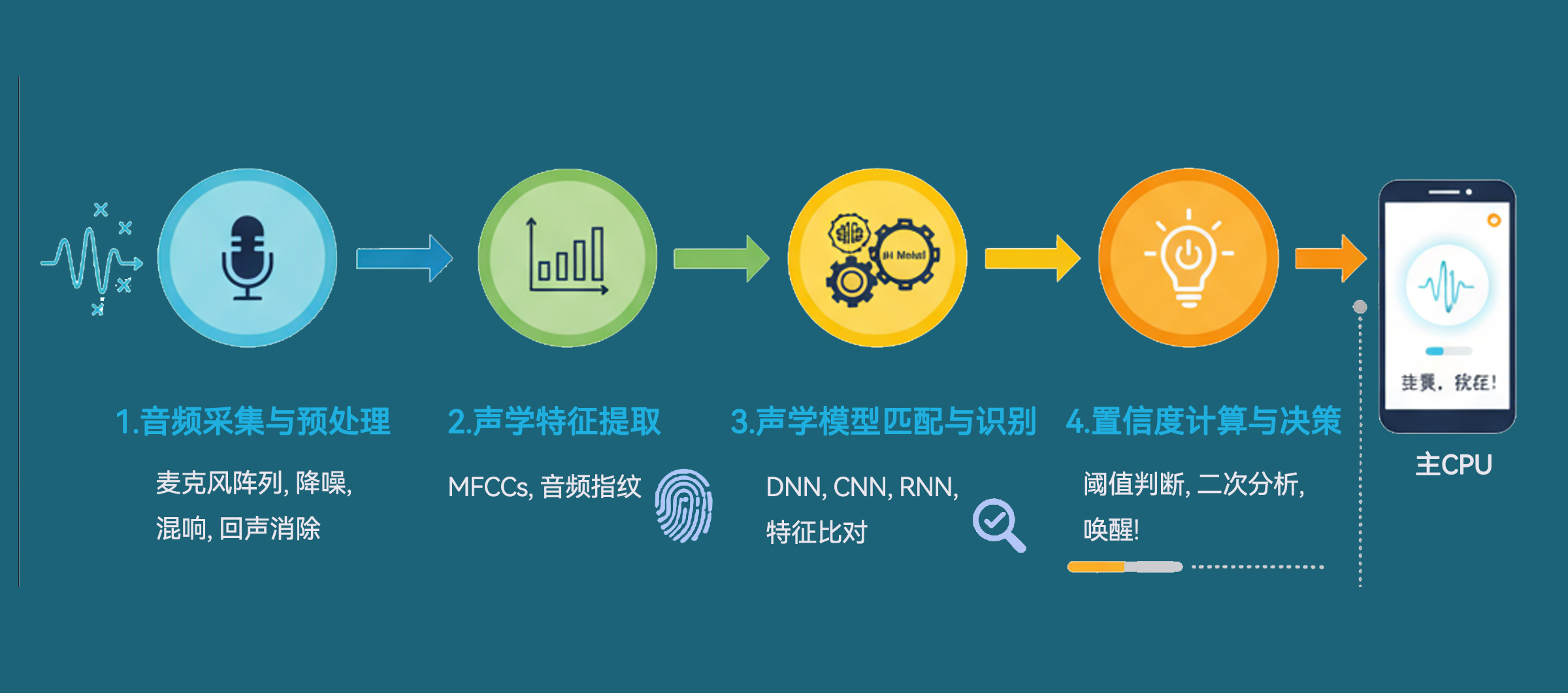
第1步:声音的采集与预处理 (Audio Acquisition & Pre-processing)
这是整个流程的起点。
麦克风阵列 (Microphone Array): 现代智能设备通常不止一个麦克风。通过麦克风阵列,设备可以实现 波束成形 (Beamforming) 技术,像“听觉上的探照灯”一样,将拾音的焦点对准发出声音的用户方向,同时抑制来自其他方向的噪音。
信号处理 (Signal Processing): 原始的音频信号会经过一系列处理,以变得更“干净”,便于识别。
回声消除 (Acoustic Echo Cancellation, AEC): 如果设备本身正在播放音乐或说话,这个技术可以防止设备把自己发出的声音当成用户的指令。
降噪 (Noise Reduction, NR): 过滤掉环境中的稳态噪音,比如空调声、风扇声等。
去混响 (Dereverberation): 消除声音在室内墙壁之间反射产生的回音,让语音信号更清晰。
第2步:声学特征提取 (Feature Extraction)
处理干净后的原始音频波形数据量巨大且复杂,不适合直接用于模型识别。因此,系统需要从中提取出最能代表语音内容的核心特征。
最经典和常用的声学特征是 梅尔频率倒谱系数 (Mel-Frequency Cepstral Coefficients, MFCC)。你可以把它理解为一种高效的“声音指纹”提取技术。它模仿人耳的听觉特性,对声音的频率进行非线性转换,最终将一小段音频(通常是25毫秒)转换成一组非常浓缩的数字(一个向量),这组数字就是这段声音的“指纹”。
第3步:声学模型匹配与识别 (Acoustic Model Matching)
这是热词唤醒技术的核心和灵魂。系统会用一个预先训练好的、专门用于识别唤醒词的 声学模型,来判断刚刚提取的声音“指纹”序列是否与唤醒词的发音匹配。
模型的小型化与高效化: 这个声学模型必须非常小,计算量也要极低,因为它需要在一个功耗只有毫瓦(mW)级别的专用硬件上运行。早期的技术使用高斯混合模型-隐马尔可夫模型 (GMM-HMM),但现在主流技术几乎都转向了更精确的 深度神经网络 (Deep Neural Networks, DNN)。
常见的神经网络结构:
DNN (深度神经网络): 基本的神经网络模型。
CNN (卷积神经网络): 最初用于图像识别,但其“局部感知”的能力很适合捕捉音频特征中的稳定模式。
RNN/LSTM (循环神经网络/长短时记忆网络): 擅长处理时序数据,能够更好地理解声音前后文的关联。
CRNN (卷积循环神经网络): 结合CNN和RNN的优点,是目前效果最好的模型之一。
这个模型就像一个高度专注的“哨兵”,它的唯一任务就是判断输入的声音片段“是唤醒词”还是“不是唤醒词”。
第4步:置信度计算与决策 (Confidence Scoring & Decision)
模型计算后,不会简单地输出“是”或“否”,而是会给出一个 置信度分数 (Confidence Score)。
设定阈值 (Threshold): 系统会预设一个置信度阈值。如果模型输出的分数高于这个阈值,系统就判定“唤醒成功”。
二次确认 (Second-stage Verification): 为了防止误唤醒,很多设备会有一个更复杂、但仍然相对低功耗的二次确认模型。当第一个“哨兵”模型觉得听到了唤醒词后,会立刻让第二个更资深的“哨兵”再听一遍,确认无误后才真正唤醒主系统。
平衡误报与漏报: 阈值的设定是一个权衡。
阈值太低: 容易误唤醒,电视里的声音或相似的发音都可能激活设备(学术上称为 “误报率” False Acceptance Rate, FAR 高)。
阈值太高: 用户可能要很大声或很标准地喊好几遍才能成功唤醒(学术上称为 “拒识率” False Rejection Rate, FRR 高)。 厂商需要通过海量数据测试,找到一个最佳的平衡点。
四、实现方式
1. 系统级唤醒 (System-Level Wake-up)
代表案例: 苹果的 "Hey Siri"、Google的 "Hey Google"、手机厂商自带的语音助手(如“小爱同学”、“小艺小艺”)。
运行方式: 正如前面原理图所示,它的核心计算是运行在一个 专用的、超低功耗的硬件(DSP或NPU) 上的。这个硬件独立于主CPU。
特点
极致低功耗: 因为在专用硬件上运行,所以即便主CPU休眠时,它也能7x24小时持续监听,而耗电量极小。
最高权限: 它可以从“深度睡眠”状态唤醒整个软件系统,点亮屏幕,启动完整功能。
最佳性能: 它可以直接调用底层的麦克风阵列,进行最优质的降噪和回声消除。
2. App级唤醒 (Application-Level Wake-up)
代表案例: 大部分第三方App内置的语音唤醒功能,例如地图App在导航时,你喊“导航去公司”;或者音乐App在播放时,你喊“下一首”。
运行方式: 它的模型和判断逻辑是作为一个 普通的软件进程,运行在手机的 主CPU 上的。
特点
功耗较高: 主CPU的功耗远高于专用DSP。如果让它24小时在后台运行,手机电池会很快耗尽。因此,操作系统(Android/iOS)会严格限制App在后台长时间占用CPU和麦克风。
权限受限: 它通常只能在App处于前台(即显示在屏幕上)时,或者在申请了短暂的后台权限时才能工作。它无法从锁屏状态下唤醒手机。
性能局限: 它从操作系统那里获取的是经过处理后的单路音频流,很难像系统级那样灵活地利用所有麦克风进行优化。
通常软件开发者,需要在上面原理图里面第三步、第四步进行开发操作:
构建声学模型: 用大量语音文件训练模型。开发者会收集成千上万条包含唤醒词的语音(正样本,如“你好小明”)和不包含唤醒词的各种语音、噪音(负样本),然后用这些数据来训练一个专门识别这个词的神经网络模型。
在软件里加载模型进行判断: 这就是将训练好的模型部署到App中,实时处理从麦克风获取的音频,并进行“第4步:置信度计算与决策”。
这两步实践,我们将在AI开发实践相关章节用实例案例来介绍和使用热词唤醒相关功能。
五、应用场景
智能家居
通过设定热词,用户可以方便地控制家中的各种设备,如开关灯、调节温度等。
车载系统:
设置与驾驶相关的热词,如导航目的地、拨打电话等,提高行车安全性和便利性。
手机助手:
利用热词技术,手机助手可以更准确地理解用户的指令,执行相应的操作。
医疗领域:
在医疗设备上设置紧急呼叫热词,以便患者在需要时快速获得帮助。
六、总结
核心概念: 热词唤醒技术,就像我们小时候听到妈妈喊自己名字“小明,回家吃饭!”一样,是一个让设备从周围万千声音中精准识别出特定“唤醒词”(如“Hey Siri”、“天猫精灵”)并激活自身的过程。它充当了人与机器进行语音交互的“第一声问候”。
核心价值(为什么需要): 引入热词唤醒主要解决了三大问题:
节能高效: 设备无需时刻开启高性能处理器,仅通过一个超低功耗的“哨兵”持续监听,极大节省了电量。
便捷自然: 用户无需任何物理接触,即可“解放双手”,在任何场景下与设备轻松交互。
明确交互起点: 为机器提供了一个清晰的信号,告诉它“现在我要对你说话了”,从而开启后续精准的语音识别与服务。
技术原理(如何实现): 整个过程是一个在极低功耗下运行的关键词识别(KWS)任务,主要分为四步:
音频采集与预处理: 利用麦克风阵列拾音,并通过降噪、回声消除等技术获得干净的人声。
声学特征提取: 将处理后的声音波形转换为一组浓缩的数字“指纹”(如MFCC)。
声学模型匹配: 使用一个轻量级、高效率的深度学习模型(如DNN/CNN/RNN),判断该“指纹”是否与预设的唤醒词匹配。
置信度决策: 模型输出一个匹配分数,当分数超过预设阈值时,判定唤醒成功,并激活主系统。
两种实现方式:
系统级唤醒: 由手机或设备厂商实现,运行在专用的低功耗硬件(DSP/NPU)上。优点是功耗极低,可7x24小时工作并唤醒整个休眠的系统。
App级唤醒: 由应用开发者实现,运行在主CPU上。缺点是功耗较高,通常只在App运行时生效,且权限受限,无法从锁屏状态唤醒设备。
主要应用场景: 这项技术已深度融入我们的生活,广泛应用于智能家居(语音控制家电)、车载系统(保障驾驶安全)、手机助手(实现便捷操作)以及医疗领域(提供紧急呼叫)等多种场景。