个人电脑部署超强大ChatGPT,支持图像识别/文生图/语音输入/文本朗读!
实现功能和效果
今天通过几个开源项目组合实现一个普通配置电脑即可运行的私有化ChatGPT,支持以下功能:
界面体验与ChatGPT官方几乎一样。
支持多种开源模型,可以聊天、写代码、识别图片内容等。
支持文生图。
支持麦克风语音输入聊天。
支持自动朗读回答结果。
支持联网使用openai。
前5个功能拔掉网线也能正常使用。先看一下本地(16G内存无GPU)断网运行的聊天与图片识别效果:

文生图效果:
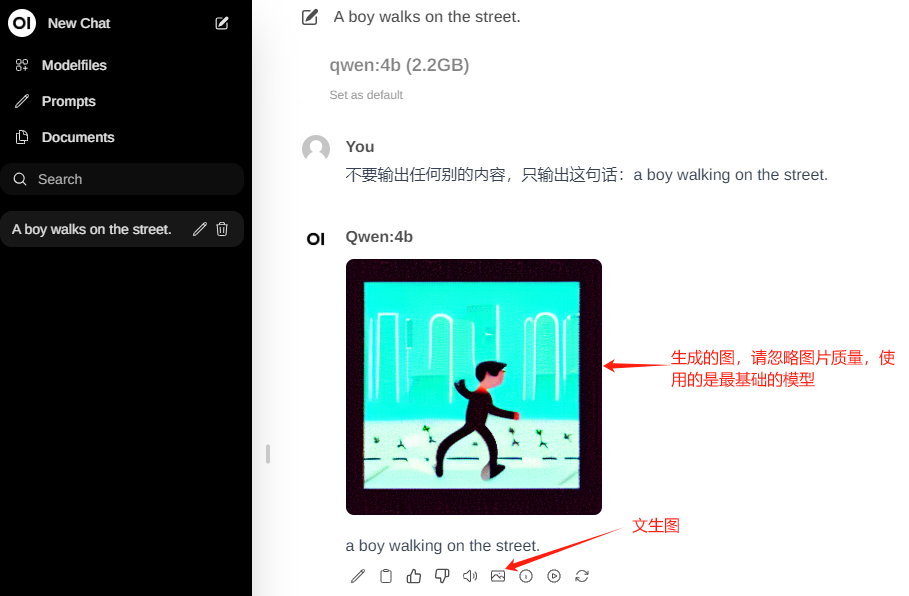
用到的开源项目(文末获取github地址):
界面:open webui,8.1k star,界面漂亮,功能丰富,我们本次主要用它将其他各开源项目组合起来。
大模型:ollama,44.8k star,支持使用CPU运行多种开源大模型,部署超级简单。
文生图:stable diffusion,124k star,最强开源文生图项目。
语音输入:openai开源的whisper, 57.1k star,CPU可用,效果可与收费产品比肩。
文本朗读:windows系统提供的接口,离线免费使用,后面有介绍。
接入openai:GPT_API_free, 13.3k star,免费的openai API key。
下面只有前两步为必须执行的,后面步骤根据自己需求决定是否执行。
实操部署
1.部署大模型
参考文章《轻松在本地运行Llama2、Gemma等多种大模型,无需GPU!》完成第一步操作即可,ollama支持多种优秀开源大模型,可根据需求多下载几种,按需使用,官方支持的模型:https://ollama.com/library
2.部署界面
open webui不仅是一个聊天界面,还是一个ollama的客户端,还有很多其他功能,感兴趣可以去github看官方文档。使用docker一键部署:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
安装完成之后,浏览器输入http://localhost:3000,选择模型就可以开始聊天了。可以到设置界面的General中设置各种模型参数,到这一步已经实现一个基本的私有化ChatGPT了。
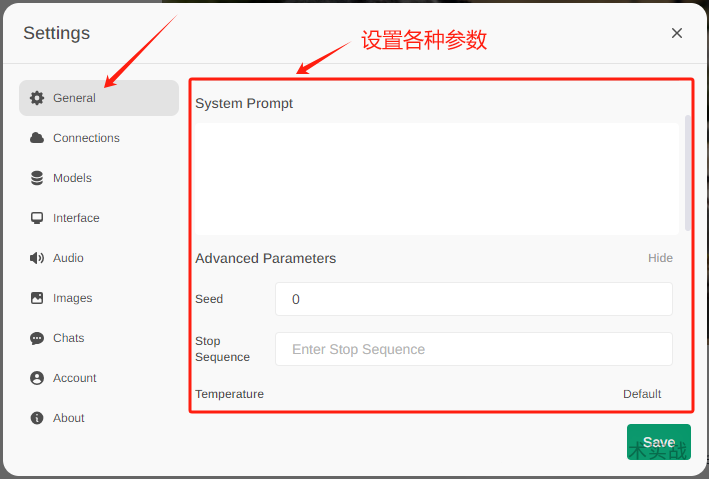
3.图片识别
先使用ollama下载llava模型,聊天时选择llava,发送图片即可。以下是作者测试的图片识别效果,连后面有多排座位,有些座位是空的都能准确识别出来!

4.语音输入
如果想使用语音输入功能,可以参考这篇文章部署 whisper:用openai开源的whisper部署自己的语音识别系统。部署好之后,将STT引擎改为whisper(Local),在聊天输入框就可以点击麦克风图标输入语音了。
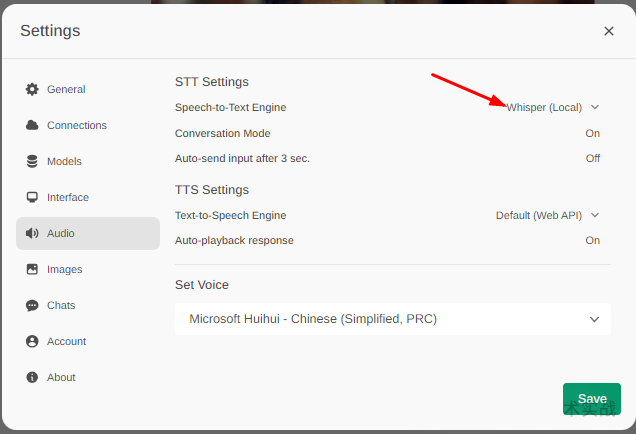
5.文生图
先本地部署stable diffusion(以下简称sd):AI绘画教程之stable diffusion【2.Windows系统本地部署】
说明:sd需要GPU,但我看sd官方文档好像支持CPU,作者未验证。

接下来坑比较多,作者已解决,照做即可。
5.1 修改webui.bat,增加参数
open-webui要调用sd的接口,因此sd要提供api,修改sd根目录中的webui.bat,增加以下代码
set COMMANDLINE_ARGS=--api如图所示:

5.2 修改user.css
open-webui要调用sd的/sdapi/v1/options接口,但是这个接口报错,解决方案:sd根目录新建文件user.css,文件内容如下:
[id^="setting_"] > div[style*="position: absolute"] {
display: none !important;
}
5.3 修改容器访问宿主机SD
双击webui.bat启动sd,进入open-webui的设置页面,按下图设置,注意:因为open-webui是在docker部署的,sd是在宿主机部署,open-webui调用sd接口相当于docker内部调用宿主机服务,所以在浏览器虽然用127.0.0.1:7860能访问sd,但是这里填写127.0.0.1是无法请求的,按图示内容填写,如果您的部署方式和作者不一样,请根据情况填写。

5.4 选择模型生成图片
生成图片的按钮只在大模型回复的内容下面才会出现,并且会把回复的内容当成sd的prompt,因此想生成图片需要先选择一个模型,让模型把你想使用的promt回复给你,然后点击生成图片按钮,就可以生成了。

6.使用openai接口
感觉本地模型运行慢,有时候想用在线的OpenAI接口?没问题!可以参照这篇获取免费的API Key:《获取免费ChatGPT API Key的开源项目》,然后按照下图配置。

配置后,模型选择列表中就会自动多出来几个openai模型,选择即可使用。
7.文本朗读功能
按下图设置即可开启朗读功能,聊天时收到完整响应后会自动朗读。

关于文本朗读的实现原理,应该是调用了某个在线的TTS服务,但是在console中看不到任何关于TTS的请求,后来查看源码才发现是用HTML5的Speech Synthesis API实现的,这个API可以调用Windows系统的TTS。以下是代码,可直接在浏览器的console中运行测试。
// 获取支持的声音列表
speechSynthesis.getVoices()
// 合成并播放语音
const speak = new SpeechSynthesisUtterance("要播放的文字");
// 选择用哪个声音
speak.voice = speechSynthesis.getVoices()[0];
// 执行这句就可以听到声音了
speechSynthesis.speak(speak);以下是测试截图:

利用这个API可以实现免费、离线的TTS功能。
开源地址
ollama:https://github.com/ollama/ollama
open-webui:https://github.com/open-webui/open-webui
stable-diffusion:https://github.com/AUTOMATIC1111/stable-diffusion-webui
whisper:https://github.com/openai/whisper
GPT_API_free:https://github.com/chatanywhere/GPT_API_free