轻松在本地运行Llama2、Gemma等多种大模型,无需GPU!
ollama这个项目可以让我们轻松在本地运行Llama2、Gemma等多种开源大模型。
项目简介
该项目吸引作者的几个特点:
支持使用CPU,普通个人电脑可运行。
一键安装,超级简单,支持windows/linux/mac。
支持Llama 2、Gemma、通义千问、LLaVA(图片识别)等多种大模型。
可提供REST API服务。
生态丰富,围绕着该项目已经产生了多种webui、桌面软件、sdk库等。
以下是作者的实战效果,注意这是本地离线运行,不需要联网。
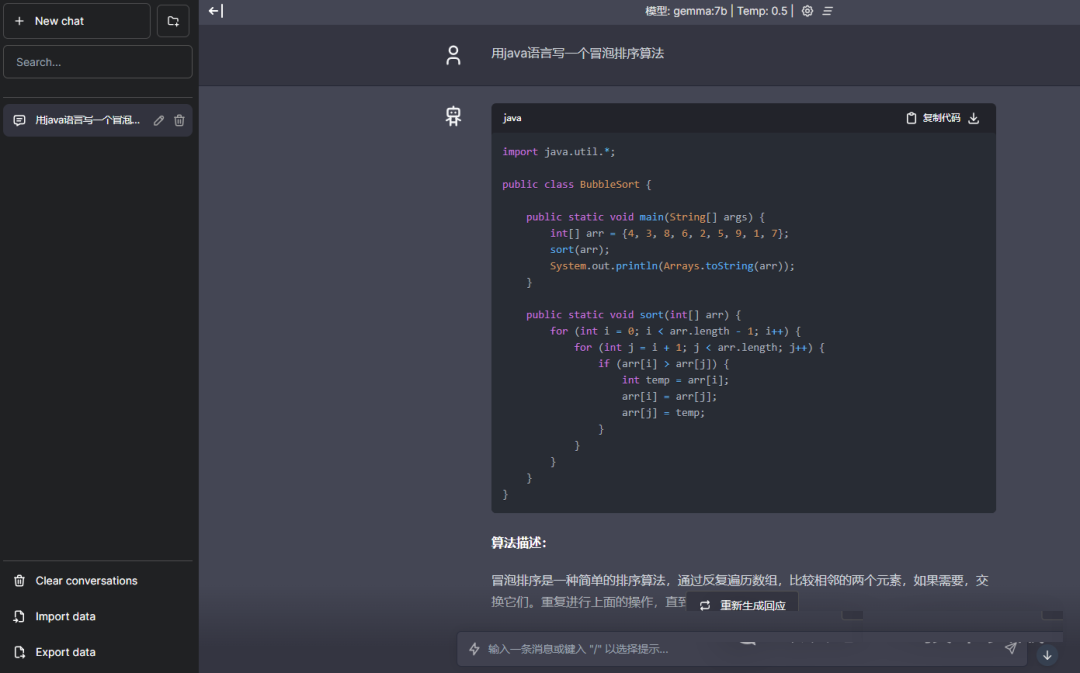
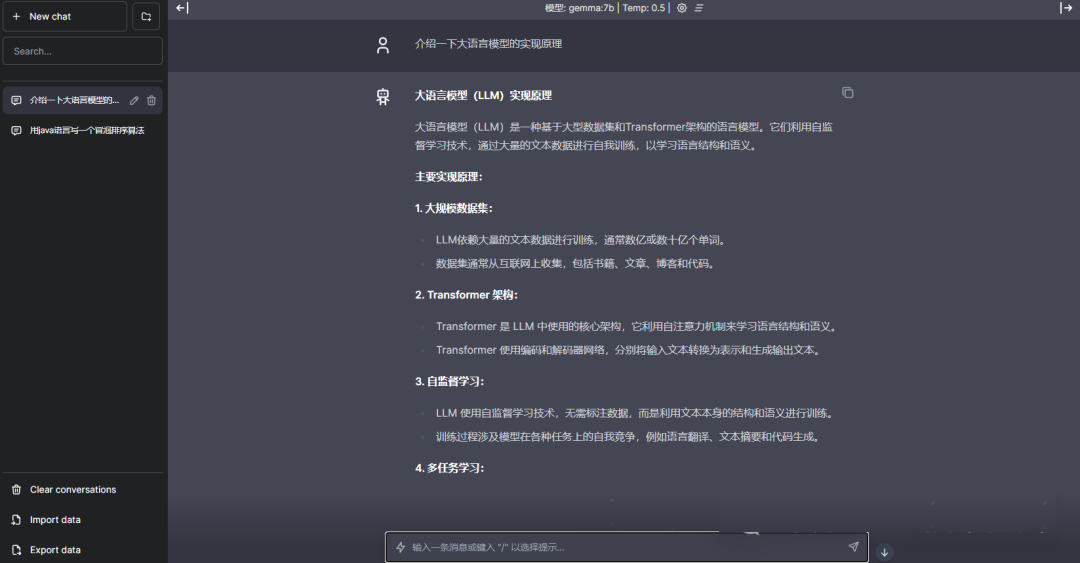
实操部署
下面跟着作者快速实现一个如上图所示的应用。
1.安装运行大模型
在项目的github主页下载windows版本。

下载后双击安装完成,在cmd中输入下面命令,一键运行Llama2模型(作者电脑16G内存,理论上8G也可以使用)。
ollama run llama2等待直至出现以下界面,即成功运行。

在"Send a messsage"处输入问题,模型就可以回答了,至此已安装成功,是不是超级简单!

2.部署web界面
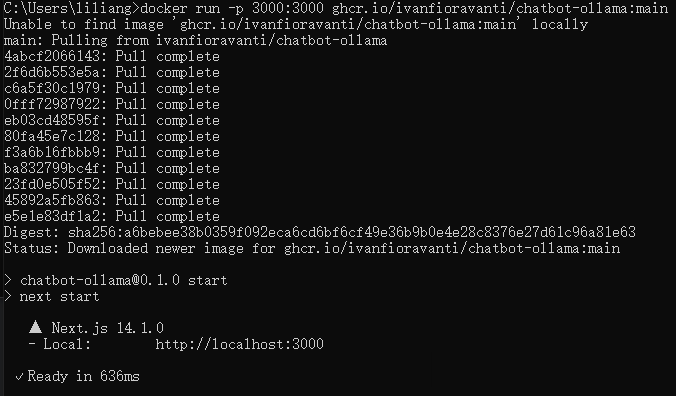
下面我们部署一个类似ChatGPT界面的web ui,运行以下docker命令。
docker run -p 3000:3000 ghcr.io/ivanfioravanti/chatbot-ollama:main如下图所示,一键部署成功。
用浏览器打开http://localhost:3000,即可像使用ChatGPT一样使用自己的私有GPT了,重点是可以离线使用,数据更安全!
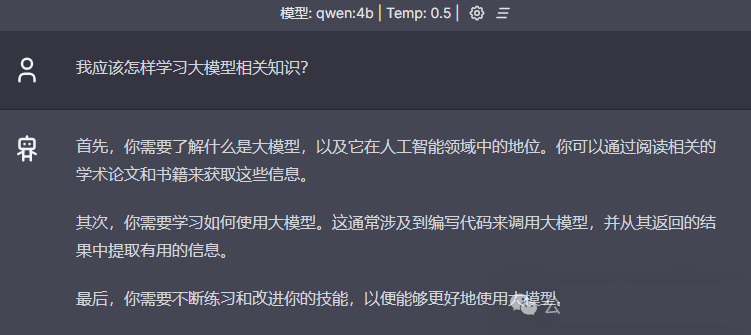
3.使用REST API
截图展示一下REST API的能力,更多参数请查阅官方文档。
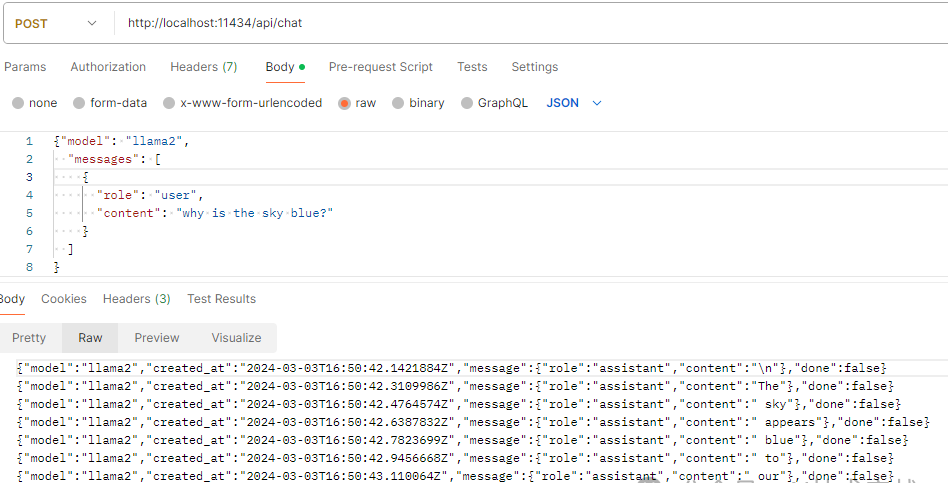
4.图片识别
根据官方文档,使用llava模型可以识别图片,下面是作者测试结果:

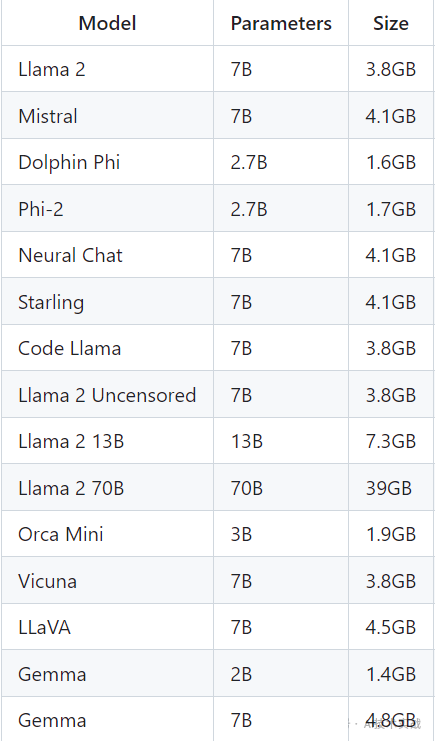
5.内存要求
支持多种模型,每种模型有多个参数,运行7B参数模型需要至少8G内存,运行13B参数模型需要至少16G内存,运行33B参数模型需要至少32G内存。以下是几种模型的参数与模型大小,更多模型可查阅官方文档。
更多功能请参考官方文档
开源地址
github地址 https://github.com/ollama/ollama