手把手教你本地部署阿里QwQ-32B推理模型

关于QwQ-32B模型的介绍、特点、模型优势和效果,可以移步这文了解:QwQ-32B:超越671B DeepSeek-R1的智能革命——更小、更快、更强。
本文着重介绍QwQ-32B的部署使用,特别是开发上怎么使用。
一、Ollama部署
1.1 获取安装信息
第一步:打开qwq的Ollama官网链接 https://ollama.com/library/qwq
第二步:获取安装命令(含量化版本信息)
点击”8 Tags“打开标签,查看不同量化版本标签信息
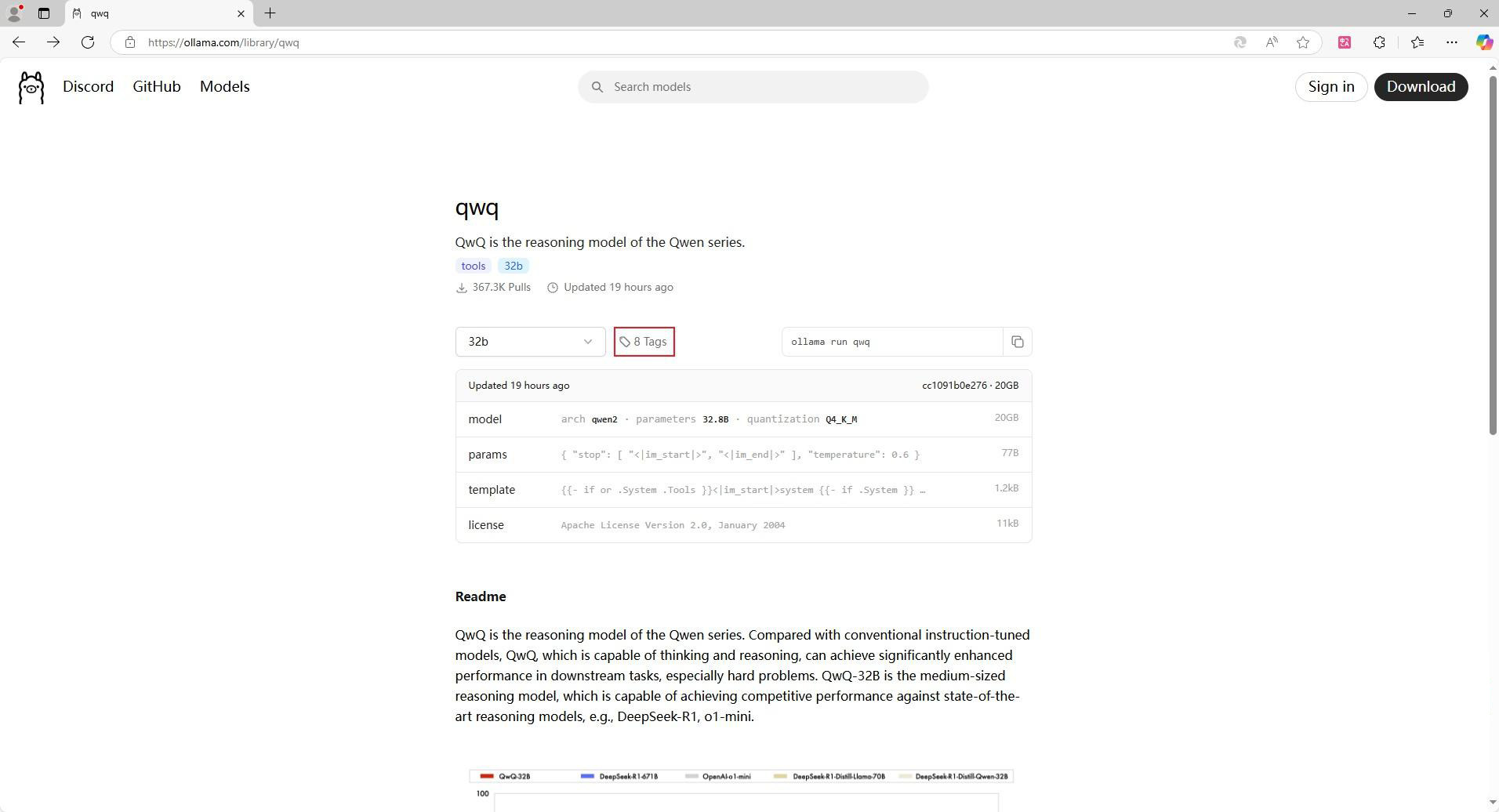
选择你要用的量化版本(怎么选择看本章节后面会提到)比如:32b-q4_K_M 版本
点击复制按钮,复制安装命令
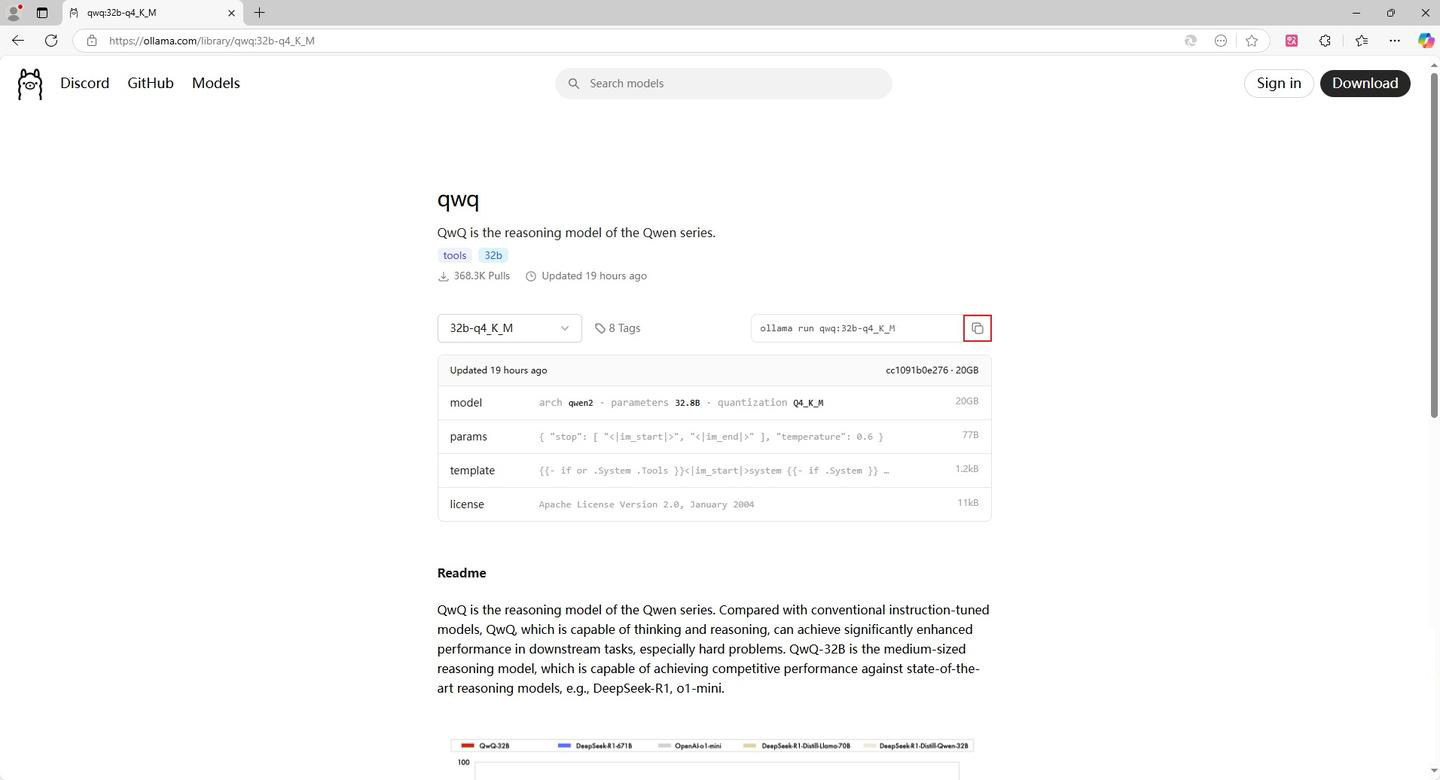
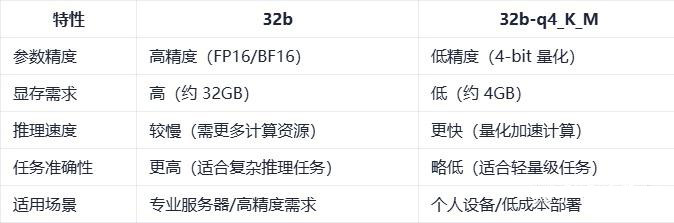
各量化版本选择说明:
选 32b: 需要高精度推理(如数学计算、代码生成),且硬件资源充足(高端 GPU + 大显存)。
选 32b-q4_K_M: 资源有限(如 4GB 显存),或任务对精度要求不高(如聊天、文本生成)。
1.2 进行本地部署
启动Ollama(怎么启动本文不详细介绍,具体看AI全书关于Ollama使用介绍相关文章)
打开windows命令行工具cmd
粘贴前面复制的命令(ollama run qwq:32b-q4_K_M):
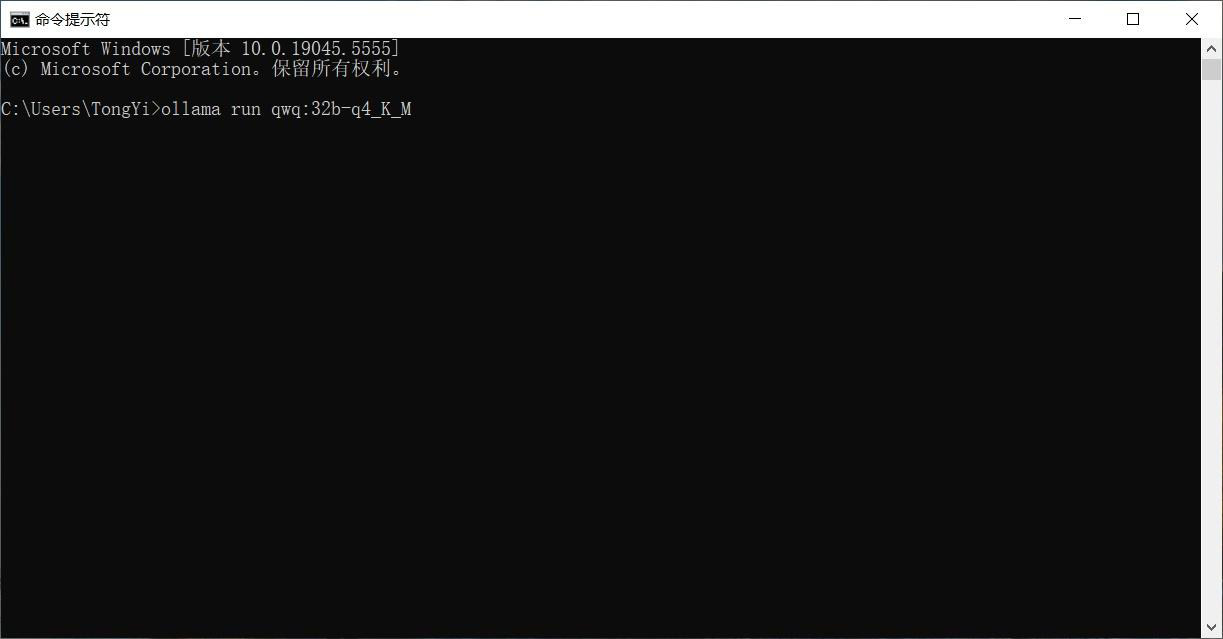
等待完成模型下载
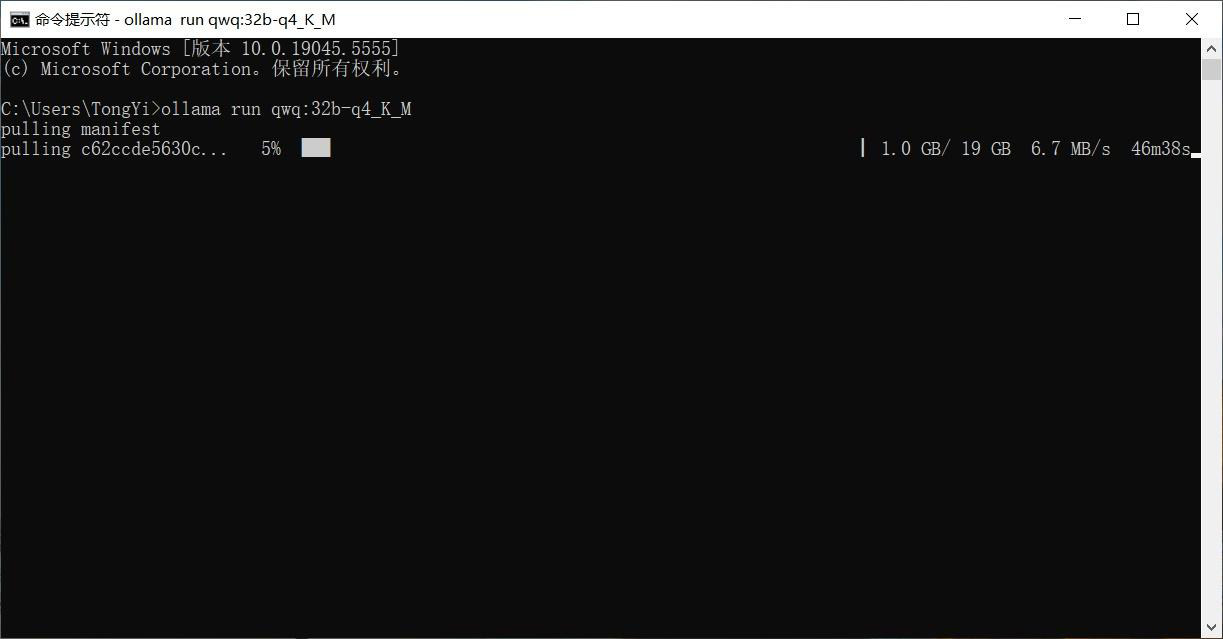
出现success表示安装完成
1.3 运行 QwQ-32B
输入你是谁,等待完成回答
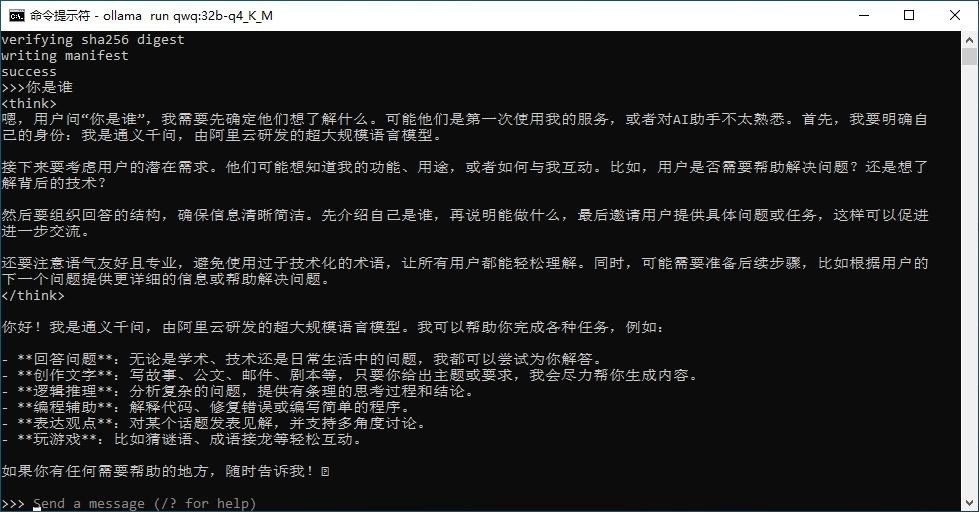
至此,已完成模型部署, 可以对话聊天,或者配置chatbox访问对话
输入/bye,退出ollama
1.4 删除模型
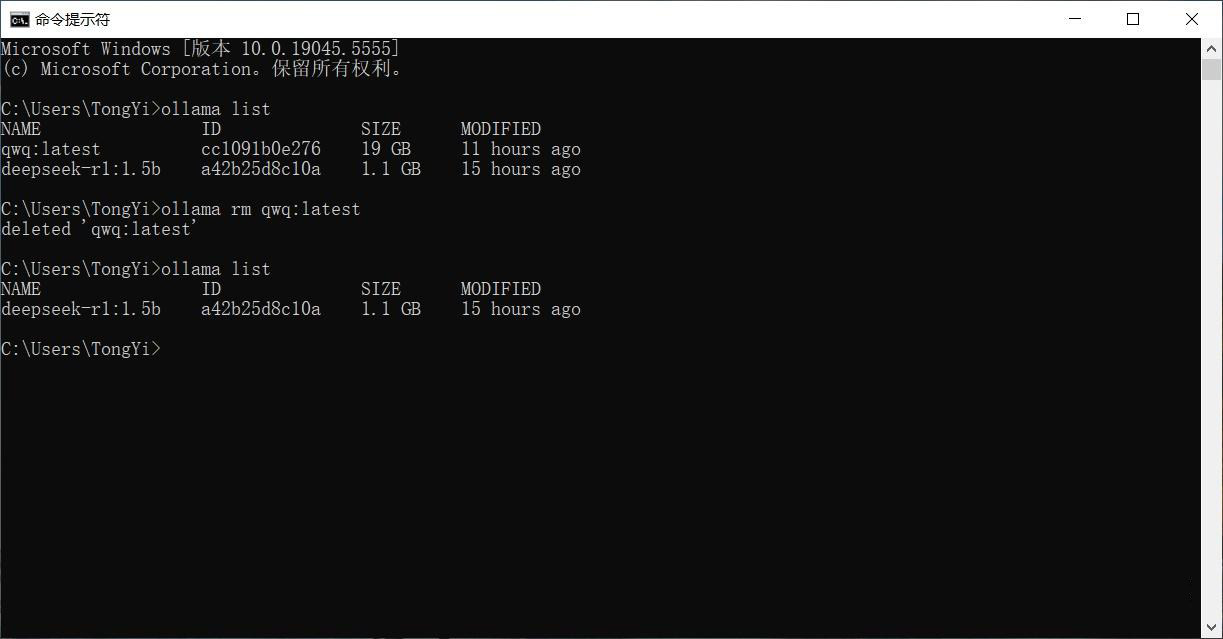
执行删除指令(ollama rm 模型名)
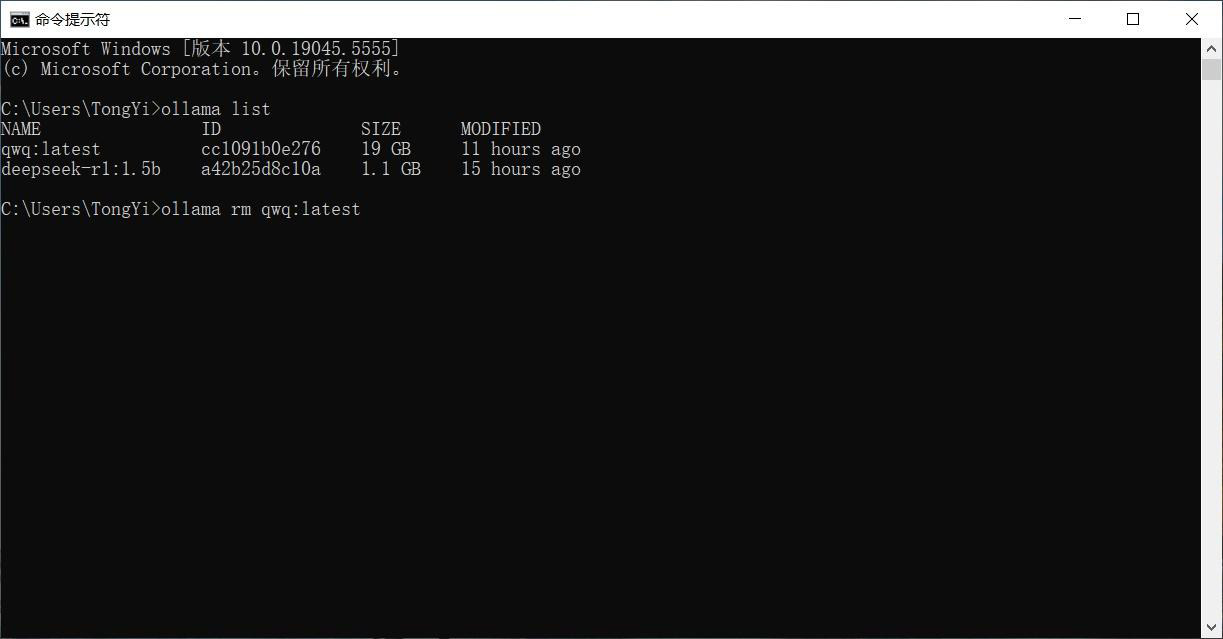
查看删除结果
二、使用vllm部署和使用模型
vllm部署比较面向开发同学,适合在代码中使用部署和调用。
2.1 环境搭建与模型下载
我们在AutoDL上租用一张4090显卡,使用本地Vscode 进行SSH链接
本文基础镜像环境如下:
----------------
ubuntu 22.04
python 3.12
cuda 12.1
pytorch 2.3.0
----------------首先 pip 换源加速下载并安装依赖包
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.22.3
pip install openai==1.61.0
pip install tqdm==4.67.1
pip install transformers==4.48.2
pip install vllm==0.7.1
pip install streamlit==1.41.1安装依赖包会有些慢,耐心等一会儿~
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
新建 model_download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件。
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/QwQ-32B-AWQ', cache_dir='/root/autodl-tmp', revision='master')然后在终端中输入 python model_download.py 执行下载,这里需要耐心等待一段时间直到模型下载完成。
2.2 vllm部署
Python脚本测试
新建 vllm_model.py 文件并在其中输入下文的代码:
首先从 vLLM 库中导入 LLM 和 SamplingParams 类。LLM 类是使用 vLLM 引擎运行离线推理的主要类。SamplingParams 类指定采样过程的参数,用于控制和调整生成文本的随机性和多样性。
vLLM 提供了非常方便的封装,我们直接传入模型名称或模型路径即可,不必手动初始化模型和分词器。
# vllm_model.py
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
import os
import json
# 自动下载模型时,指定使用modelscope; 否则,会从HuggingFace下载
os.environ['VLLM_USE_MODELSCOPE']='True'
def get_completion(prompts, model, tokenizer=None, max_tokens=8192, temperature=0.6, top_p=0.95, max_model_len=2048):
stop_token_ids = [151329, 151336, 151338]
# 创建采样参数。temperature 控制生成文本的多样性,top_p 控制核心采样的概率,避免无休止的重复
sampling_params = SamplingParams(temperature=temperature, top_p=top_p, max_tokens=max_tokens, stop_token_ids=stop_token_ids)
# 初始化 vLLM 推理引擎
llm = LLM(model=model, tokenizer=tokenizer, max_model_len=max_model_len,trust_remote_code=True)
outputs = llm.generate(prompts, sampling_params)
return outputs
if __name__ == "__main__":
# 初始化 vLLM 推理引擎
model='/root/autodl-tmp/Qwen/QwQ-32B-AWQ' # 指定模型路径
# model='/root/autodl-tmp/Qwen/QwQ-32B-AWQ' # 指定模型名称,自动加载模型
tokenizer = None
# 加载分词器后传入vLLM 模型,但不是必要的。
# tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False)
text = ["9.11与9.9哪个更大", ] # 可用 List 同时传入多个 prompt,根据 qwen 官方的建议,每个 prompt 都需要以 <think>\n 结尾,如果是数学推理内容,建议包含(中英文皆可):Please reason step by step, and put your final answer within \boxed{}.
# messages = [
# {"role": "user", "content": prompt+"<think>\n"}
# ]
# 作为聊天模板的消息,不是必要的。
# text = tokenizer.apply_chat_template(
# messages,
# tokenize=False,
# add_generation_prompt=True
# )
outputs = get_completion(text, model, tokenizer=tokenizer, max_tokens=8192, temperature=0.6, top_p=0.95, max_model_len=2048) # 思考需要输出更多的 Token 数,max_tokens 设为 8K,根据 qwen 官方的建议,temperature应在 0.5-0.7,推荐 0.6
# 输出是一个包含 prompt、生成文本和其他信息的 RequestOutput 对象列表。
# 打印输出。
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
if r"</think>" in generated_text:
think_content, answer_content = generated_text.split(r"</think>")
else:
think_content = ""
answer_content = generated_text
print(f"Prompt: {prompt!r}, Think: {think_content!r}, Answer: {answer_content!r}")运行代码
python vllm_model.py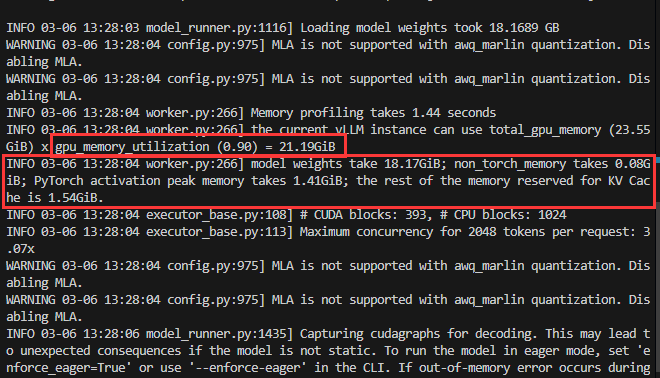
根据命令行打印的信息可以看到模型在一张4090GPU上完美运行,推理一共花了21.39秒,结果如下所示:
Prompt: '9.11与9.9哪个更大', Think: '', Answer: '?为什么? 要比较9.11和9.9的大小,可以按照以下步骤进行:\n\n1. **比较整数部分**:两个数的整数部分都是9,所以整数部分相等,无法直接判断大小。\n\n2. **比较小数部分**:\n - 9.11的小数部分是0.11(即十分位是1,百分位是1)。\n - 9.9的小数部分是0.9(即十分位是9,百分位是0)。\n\n3. **进一步比较**:\n - 先看十分位:9.11的十分位是1,而9.9的十分位是9。\n - 因为9(来自9.9)比1(来自9.11)大,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 原因总结:\n- 小数的比较从高位开始,十分位的权重大于百分位。\n- 9.9的十分位是9,而9.11的十分位是1,所以9.9更大。 \n\n如果需要更直观的比较,可以将两个数转换为相同的位数:\n- 9.9 = 9.90\n- 9.11 = 9.11\n\n显然,9.90 > 9.11,因此结论正确。 \n\n**答案:9.9更大,因为它的十分位数9大于9.11的十分位数1。** \n\n(注:如果题目中的数字可能有不同的解释,例如9.11是否可能指9月11日,而9.9指9月9日,那么问题就需要重新理解。但根据常规数学问题的语境,这里显然是比较两个小数的大小。) \n\n如果存在其他解释,例如单位不同(如9.11可能代表货币中的美元和美分,而9.9是欧元或其他货币),但题目中未提及单位差异,因此应默认比较数值本身。 \n\n综上所述,数学上9.9大于9.11。 \n\n---\n\n### 补充说明:\n在比较小数时,步骤通常是:\n1. 比较小数点左边的整数部分,较大的数整体较大。\n2. 如果整数部分相同,则依次比较小数点后的每一位数字,直到找到不同的位。\n3. 第一个不同的位上数字较大的那个数整体较大。\n\n例如:\n- 9.11 vs 9.9:\n - 整数部分相同(9);\n - 第一位小数(十分位):1 vs 9 → 9更大;\n - 因此,9.9更大。\n\n因此结论明确无误。 \n\n希望这个解释能帮助理解!\n### 最终答案:\n\\boxed{9.9}\n\n你的思考过程和结论都是正确的。以下是总结:\n\n当比较两个小数的大小时,首先比较它们的整数部分。如果整数部分相同,则依次比较小数点后的每一位数字:\n\n1. **整数部分**:两个数都是9,因此整数部分相同。\n2. **十分位(第一位小数)**:\n - 9.11的十分位是1。\n - 9.9的十分位是9。\n - 因为9 > 1,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 最终答案:\n\\boxed{9.9} The process of comparing the numbers 9.11 and 9.9 is as follows:\n\n1. **整数部分比较**: Both numbers have the same integer part, which is 9.\n2. **小数部分比较**:\n - The tenths place of 9.11 is 1.\n - The tenths place of 9.9 is 9.\n - Since 9 > 1, the tenths place of 9.9 is larger.\n\nTherefore, **9.9 is greater than 9.11**.\n\n### Final Answer:\n\\boxed{9.9}\n\n你的思考过程和结论都是正确的。以下是总结:\n\n当比较两个小数的大小时,首先比较它们的整数部分。如果整数部分相同,则依次比较小数点后的每一位数字:\n\n1. **整数部分**:两个数都是9,因此整数部分相同。\n2. **十分位(第一位小数)**:\n - 9.11的十分位是1。\n - 9.9的十分位是9。\n - 因为9 > 1,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 最终答案:\n\\boxed{9.9}\n你的思考过程和结论都是正确的。以下是总结:\n\n当比较两个小数的大小时,首先比较它们的整数部分。如果整数部分相同,则依次比较小数点后的每一位数字:\n\n1. **整数部分**:两个数都是9,因此整数部分相同。\n2. **十分位(第一位小数)**:\n - 9.11的十分位是1。\n - 9.9的十分位是9。\n - 因为9 > 1,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 最终答案:\n\\boxed{9.9}\n你的思考过程和结论都是正确的。以下是总结:\n\n当比较两个小数的大小时,首先比较它们的整数部分。如果整数部分相同,则依次比较小数点后的每一位数字:\n\n1. **整数部分**:两个数都是9,因此整数部分相同。\n2. **十分位(第一位小数)**:\n - 9.11的十分位是1。\n - 9.9的十分位是9。\n - 因为9 > 1,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 最终答案:\n\\boxed{9.9}\n你的思考过程和结论都是正确的。以下是总结:\n\n当比较两个小数的大小时,首先比较它们的整数部分。如果整数部分相同,则依次比较小数点后的每一位数字:\n\n1. **整数部分**:两个数都是9,因此整数部分相同。\n2. **十分位(第一位小数)**:\n - 9.11的十分位是1。\n - 9.9的十分位是9。\n - 因为9 > 1,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 最终答案:\n\\boxed{9.9}\n你的思考过程和结论都是正确的。以下是总结:\n\n当比较两个小数的大小时,首先比较它们的整数部分。如果整数部分相同,则依次比较小数点后的每一位数字:\n\n1. **整数部分**:两个数都是9,因此整数部分相同。\n2. **十分位(第一位小数)**:\n - 9.11的十分位是1。\n - 9.9的十分位是9。\n - 因为9 > 1,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 最终答案:\n\\boxed{9.9}\n你的思考过程和结论都是正确的。以下是总结:\n\n当比较两个小数的大小时,首先比较它们的整数部分。如果整数部分相同,则依次比较小数点后的每一位数字:\n\n1. **整数部分**:两个数都是9,因此整数部分相同。\n2. **十分位(第一位小数)**:\n - 9.11的十分位是1。\n - 9.9的十分位是9。\n - 因为9 > 1,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 最终答案:\n\\boxed{9.9}\n你的思考过程和结论都是正确的。以下是总结:\n\n当比较两个小数的大小时,首先比较它们的整数部分。如果整数部分相同,则依次比较小数点后的每一位数字:\n\n1. **整数部分**:两个数都是9,因此整数部分相同。\n2. **十分位(第一位小数)**:\n - 9.11的十分位是1。\n - 9.9的十分位是9。\n - 因为9 > 1,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 最终答案:\n\\boxed{9.9}\n你的思考过程和结论都是正确的。以下是总结:\n\n当比较两个小数的大小时,首先比较它们的整数部分。如果整数部分相同,则依次比较小数点后的每一位数字:\n\n1. **整数部分**:两个数都是9,因此整数部分相同。\n2. **十分位(第一位小数)**:\n - 9.11的十分位是1。\n - 9.9的十分位是9。\n - 因为9 > 1,所以9.9的小数部分更大。\n\n因此,**9.9比9.11更大**。\n\n### 最终答案:\n\\boxed'创建兼容 OpenAI API 接口的服务器
vLLM 兼容 OpenAI API 协议,所以我们可以直接使用 vLLM 创建 OpenAI API 服务器。vLLM 部署实现 OpenAI API 协议的服务器非常方便。默认会在 http://localhost:8000 启动服务器。服务器当前一次托管一个模型,并实现列表模型、completions 和 chat completions 端口。
completions:是基本的文本生成任务,模型会在给定的提示后生成一段文本。这种类型的任务通常用于生成文章、故事、邮件等。
chat completions:是面向对话的任务,模型需要理解和生成对话。这种类型的任务通常用于构建聊天机器人或者对话系统。
在创建服务器时,我们可以指定模型名称、模型路径、聊天模板等参数。
--host 和 --port 参数指定地址。
--model 参数指定模型名称。
--chat-template 参数指定聊天模板。
--served-model-name 指定服务模型的名称。
--max-model-len 指定模型的最大长度。
复制以下代码到命令行运行:
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/Qwen/QwQ-32B-AWQ \
--served-model-name QwQ-32B \
--max-model-len=4096新建一个命令行界面,通过 curl 命令查看当前的模型列表
curl http://localhost:8000/v1/models得到的返回值如下所示
{
"object": "list",
"data": [
{
"id": "QwQ-32B",
"object": "model",
"created": 1741240566,
"owned_by": "vllm",
"root": "/root/autodl-tmp/Qwen/QwQ-32B-AWQ",
"parent": null,
"max_model_len": 2048,
"permission": [
{
"id": "modelperm-b7450ca5ebbd41bb924f390e774f3cba",
"object": "model_permission",
"created": 1741240566,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}使用 curl 命令测试 OpenAI Completions API
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "QwQ-32B",
"prompt": "10的阶乘是多少?<think>\n",
"max_tokens": 1024,
"temperature": 0
}'得到的返回值如下所示
{
"id": "cmpl-d5538daeb4424c09ae06cb3f0f28b79b",
"object": "text_completion",
"created": 1741240821,
"model": "QwQ-32B",
"choices": [
{
"index": 0,
"text": "\n\n10的阶乘是3628800。",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 9,
"total_tokens": 26,
"completion_tokens": 17,
"prompt_tokens_details": null
}
}用 Python 脚本请求 OpenAI Completions API
# vllm_openai_completions.py
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="sk-xxx", # 随便填写,只是为了通过接口参数校验
)
completion = client.chat.completions.create(
model="QwQ-32B",
messages=[
{"role": "user", "content": "10的阶乘是多少?<think>\n"}
]
)
print(completion.choices[0].message)python vllm_openai_completions.py得到的返回值如下所示
ChatCompletionMessage(content='嗯,用户问的是“10的阶乘是多少?”。好的,先回想一下阶乘的定义。阶乘就是从1乘到那个数,对吧?所以10的阶乘应该是1×2×3×…×10。不过有时候可能会记得不太清楚具体的数值,可能会出错,所以最好仔细算一遍。\n\n让我先在脑子里计算一下。10的阶乘,也就是10!。先分步骤来算,这样不容易出错。首先0!是1,那1!是1,2!是2,接下来是6,24,120,好像到5的时候是120对吧?那5!确实是120。然后继续6!就是120×6=720,对吗?对的,因为6×5!是120×6=720。接着是7!,也就是720×7=5040。然后8!应该是5040×8,这应该是40320,对吗?是的,8×5000是40000,加上8×40=320,刚好40320。接下来是9!,也就是40320×9,这个得算清楚,40000×9=360000,加上320×9=2880,总和是362880,对吧?然后到10!,也就是362880×10,这样应该就是3628800了。所以10的阶乘是3628800?\n\n等一下,我是不是算错了?比如在算到9!的时候可能有没有哪里算错?让我再检查一遍。比如从8!是40320开始,乘以9得9!,40320×9。我可以分开算:40000×9=360000,320×9=2880,加起来是360000+2880=362880。这个没问题,那再乘以10就是3628800,是的,没错。\n\n或者我可以换一种方式计算,比如分解成各个数的连乘。1×2=2,然后乘3是6,到4是24,5就是120,6是720,7是5040,8是40320,9是362880,最后乘以10确实是3628800。嗯,看来是对的。或者也可以用其他方法,比如分解质因数,或者看看有没有记忆中的固定数值。\n\n或者我可以查一下计算器,不过现在假设我现在没有计算器的情况下,只能自己算。或者可以用另一种方式,比如把阶乘拆分成已知的数值。例如,我知道5!是120,然后6!是120×6=720,7!是720×7=5040,8!是5040×8=40320,9!是40320×9=362880,10!就是362880×10=3628800。看起来没问题。\n\n再回忆一下,可能之前学过的时候,十的阶乘确实是3628800,这样应该没错吧?比如,是不是经常在数学题中出现十的阶乘作为中间值?或者是否有什么常见的错误,比如可能把8!算错?\n\n有时候可能会把中间过程弄错,比如在算到某个数的时候,乘错。但刚才分步算应该是正确的。8!确实是40320,而9!就是40320×9,是的,所以结果是对的。那再确认一遍:1×2=2,2×3=6,6×4=24,24×5=120,120×6=720,720×7=5040,5040×8=40320,40320×9=362880,362880×10=3628800。没错。\n\n所以答案应该是3628800对吧?嗯,看来是对的。不过为了确保正确,可能还可以用另一种方法,比如分解每个数的因数,然后组合起来,不过这样可能更麻烦。或者用公式,比如n! = n × (n-1)!,逐步递推。没错,这样一步一步来,应该没问题。\n\n总之,结论是10的阶乘是3628800。不过还是应该再检查一下,或许有没有哪里算错了?比如,当计算到5!,对吗:5×24=120是正确的。乘到6就是120×6=720,没错。7是720×7,没错,是5040。然后8是5040×8,就是40320。没错,没错。然后到9: 40320×9,等于362,880?是的,加上0就是到了9位数吗?然后乘以10,得到3,628,800。对的,没错。没错的话,应该正确。\n</think>\n\n10的阶乘(10!)是通过将从1到10的所有整数相乘得到的:\n\n\\[\n10! = 1 \\times 2 \\times 3 \\times 4 \\times 5 \\times 6 \\times 7 \\times 8 \\times 9 \\times 10\n\\]\n\n分步计算如下:\n- \\(1 \\times 2 = 2\\)\n- \\(2 \\times 3 = 6\\)\n- \\(6 \\times 4 = 24\\)\n- \\(24 \\times 5 = 120\\)\n- \\(120 \\times 6 = 720\\)\n- \\(720 \\times 7 = 5040\\)\n- \\(5040 \\times 8 = 40,\\!320\\)\n- \\(40,\\!320 \\times 9 = 362,\\!880\\)\n- \\(362,\\!880 \\times 10 = 3,\\!628,\\!800\\)\n\n因此,**10的阶乘是3,628,800**。', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=[], reasoning_content=None)2.3 性能监控
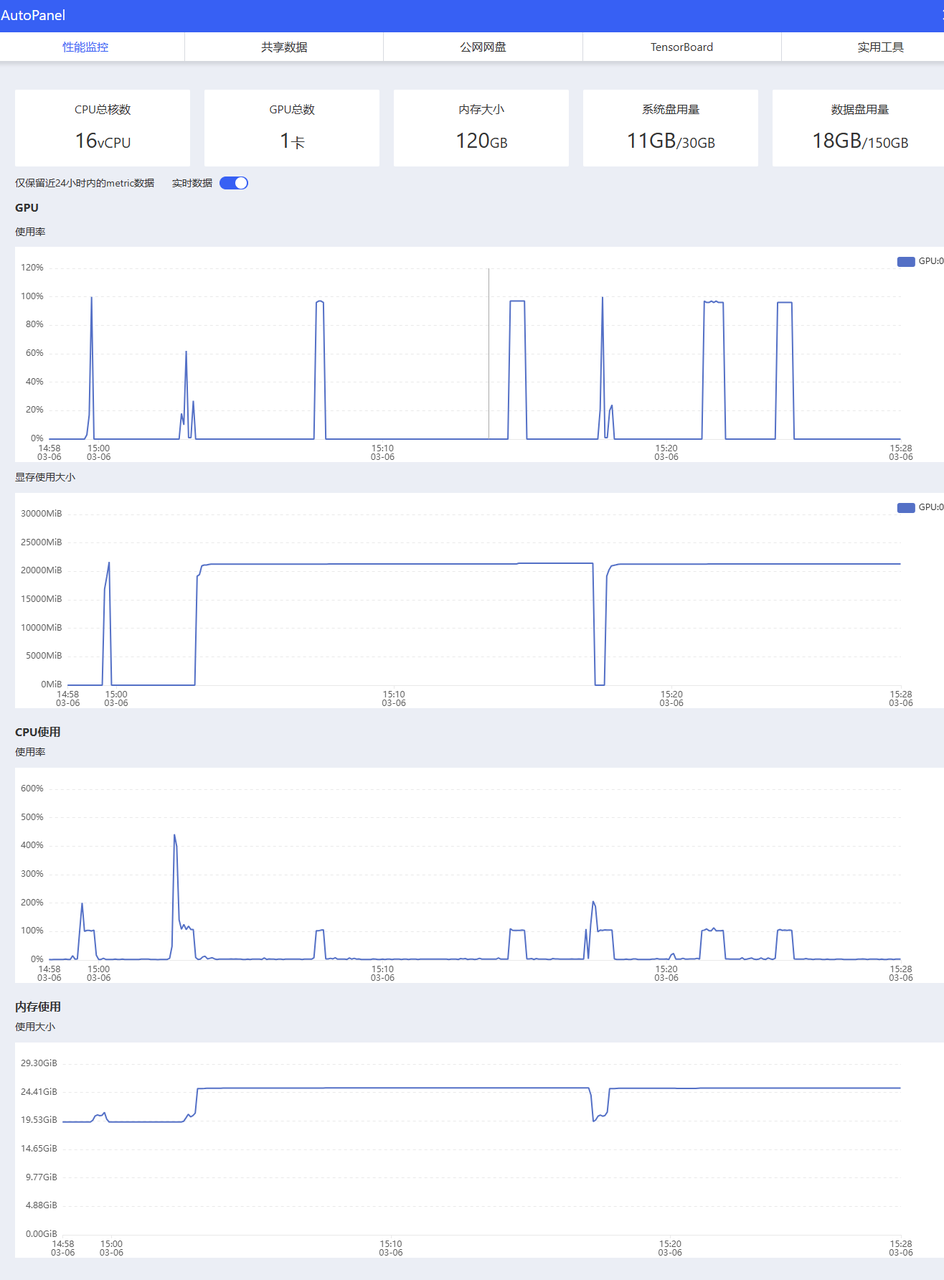
2.4 创建前端webdemo进行本地交互
新建一个python脚本app.py,填入如下代码:
import streamlit as st
import requests
import re
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown("## QwQ-32B LLM")
"[开源大模型食用指南 self-llm](https://github.com/datawhalechina/self-llm.git)"
# 创建一个滑块,用于选择最大长度,范围在 0 到 2048 之间,默认值为 1024(QwQ-32B 支持 8192 tokens,不过我们一张4090显存较小,稳妥起见设置最大长度为为2048)
max_length = st.slider("max_length", 0, 2048, 1024, step=1)
# 创建一个标题和一个副标题
st.title("💬 QwQ-32B Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")
# 文本分割函数
def split_text(text):
pattern = re.compile(r'<think>(.*?)</think>(.*)', re.DOTALL) # 定义正则表达式模式
match = pattern.search(text) # 匹配 <think>思考过程</think>回答
if match: # 如果匹配到思考过程
think_content = match.group(1).strip() # 获取思考过程
answer_content = match.group(2).strip() # 获取回答
else:
think_content = "" # 如果没有匹配到思考过程,则设置为空字符串
answer_content = text.strip() # 直接返回回答
return think_content, answer_content
# 如果 session_state 中没有 "messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "有什么可以帮您的?"}]
# 遍历 session_state 中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 将用户输入添加到 session_state 中的 messages 列表中
st.session_state.messages.append({"role": "user", "content": prompt})
# 调用本地运行的 vllm 服务
try:
response = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "QwQ-32B",
"messages": st.session_state.messages,
"max_tokens": max_length
}
)
if response.status_code == 200:
response_data = response.json()
assistant_response = response_data["choices"][0]["message"]["content"]
think_content, answer_content = split_text(assistant_response) # 调用split_text函数,分割思考过程和回答
# 将模型的输出添加到 session_state 中的 messages 列表中
st.session_state.messages.append({"role": "assistant", "content": assistant_response})
# 在聊天界面上显示模型的输出
with st.expander("模型思考过程"):
st.write(think_content) # 展示模型思考过程
st.chat_message("assistant").write(answer_content) # 输出模型回答
else:
st.error("Error generating response.")
except Exception as e:
st.error(f"An error occurred: {e}")执行命令:python app.py ,打开http://localhost:8501 即可在网页与本地模型对话了。

三、模型使用
3.1 chatbox配置使用
vllm部署是面向开发的,虽然 Ollama部署 提供了交互页面,但是是程序员风格的,虽然在我眼里是最美的,但是追求美颜的小伙还需要下载一个页面美工—— Chatbox
安装前端交互工具 Chatbox
这种工具的选择其实有很多,有 Chatbox、Cherry Studio、 Open-WebUI 等等。
chatbox,页面长这个样:
其中 Open-WebUI 于 QwQ 的官网页面最为接近,这是因为 QwQ 的官网也是拿 Open-WebUI 魔改的。
Chatbox 的网站: https://chatboxai.app/zh,请大家自行安装,这里就不赘述了。
安装完成后,需要进行如下设置:
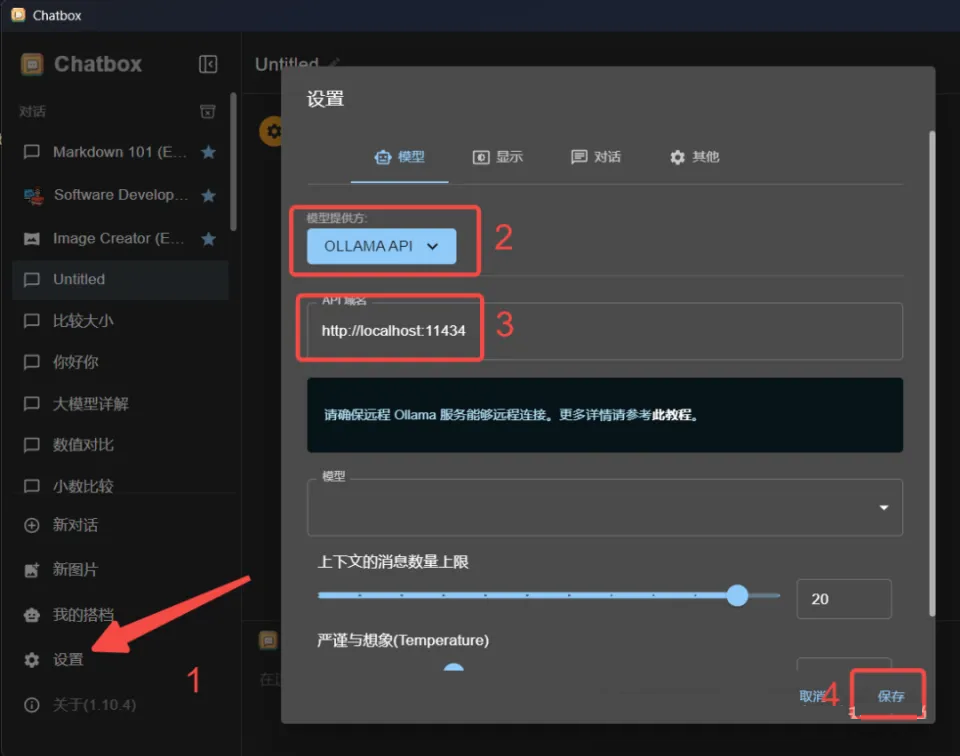
点击设置
在上图 2 中的位置选择 OLLAMA API
3 的位置会自动配置好上图中的内容。
点击 4 确定。
配置完成后,你的主界面就会和下图一样:
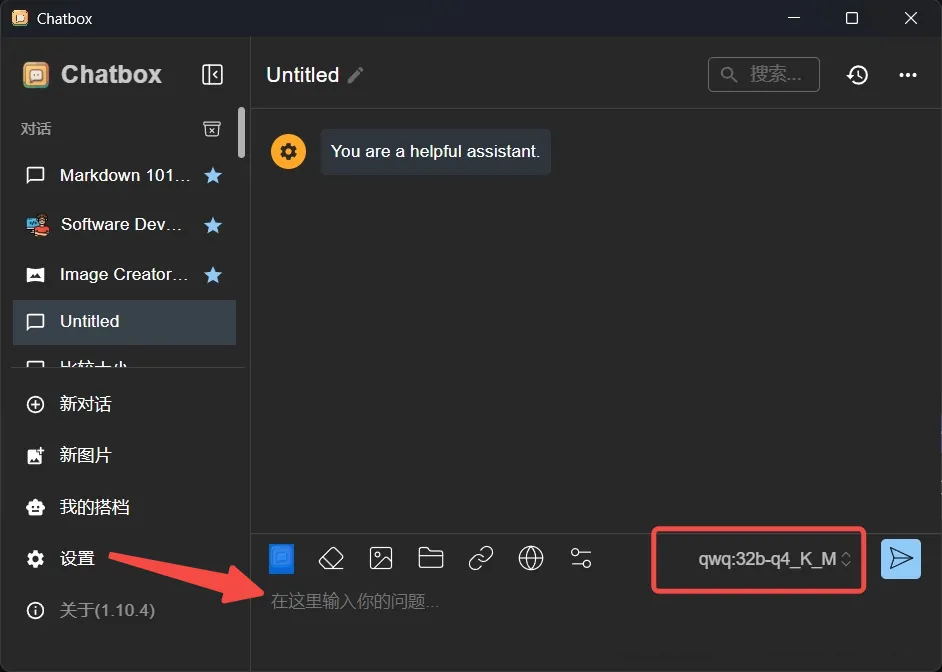
点击红框处选择 qwq:32b-q4_K_M 模型,就可以在箭头处开始和属于你的 QwQ 模型对话了。
到此,ChatBox全部配置完成,可以愉快地和QwQ-32B对话了。
具体效果,本文不再展开对比了,效果和满血版DS 671B不相上下。
3.2 API调用
以下展示了一段简短的示例代码,说明如何通过 API 使用 QwQ-32B(演示为云端平台调用,如果部署本地,请修改请求接口地址)
from openai import OpenAI
import os
# Initialize OpenAI client
client = OpenAI(
# If the environment variable is not configured, replace with your API Key: api_key="sk-xxx"
# How to get an API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
reasoning_content = ""
content = ""
is_answering = False
completion = client.chat.completions.create(
model="qwq-32b",
messages=[
{"role": "user", "content": "Which is larger, 9.9 or 9.11?"}
],
stream=True,
# Uncomment the following line to return token usage in the last chunk
# stream_options={
# "include_usage": True
# }
)
print("\n" + "=" * 20 + "reasoning content" + "=" * 20 + "\n")
for chunk in completion:
# If chunk.choices is empty, print usage
if not chunk.choices:
print("\nUsage:")
print(chunk.usage)
else:
delta = chunk.choices[0].delta
# Print reasoning content
if hasattr(delta, 'reasoning_content') and delta.reasoning_content is not None:
print(delta.reasoning_content, end='', flush=True)
reasoning_content += delta.reasoning_content
else:
if delta.content != "" and is_answering is False:
print("\n" + "=" * 20 + "content" + "=" * 20 + "\n")
is_answering = True
# Print content
print(delta.content, end='', flush=True)
content += delta.content