消费级显卡部署DeepSeek-R1满血版部署教程
DeepSeek R1满血版模型是一个671B的超大尺寸模型,正常部署需要至少1200G显存左右,哪怕是半精度运行,也需要490G以上的显存,需要8卡A100服务器才能带动,这对于普通用户来说成本还是非常大的
现在,借助KTransformers,我们可以将部分模型权重加载到内存上,并且分配部分计算工作由CPU完成,从而大幅降低GPU的负载!
但是由于KTransformers需要深度挖掘硬件计算性能,因此部署和调用会需涉及到非常多硬件底层的库,项目部署和使用门槛很高。
很多bug全网都没有解决方案!

硬件配置:
CPU: Intel Xeon Silver 4310 CPU @ 2.10GHz
内存: 系统配备了1T的DDR4内存,频率为3200MHz。
GPU: NVIDIA GeForce RTX 3090,显存为24GB。
DeepSeek R1部署方案综述
DeepSeek R1和DeepSeek V3都是默认BF8精度,是一种低精度的浮点数格式。
BF8的全称是"Brain Floating Point",由Google提出,主要用于大规模计算任务。与常见的16位浮点数(FP16)不同,BF8采用了8位尾数和8位指数的结构,能够在保证精度的同时减少计算和内存开销。
BF8的设计目标是减少计算量并保持数值稳定性,特别是在机器学习模型训练中,能在加速硬件上提供比FP32更好的性能。
在此情况下,如何以更少的成本获得尽可能好的模型性能——也就是如何进行DeepSeek R1的高性能部署,就成了重中之重。基本来说,目前的解决方案有以下三种:
1..采用“强推理、弱训练”的硬件配置
如选择国产芯片、或者采购DeepSeek一体机、甚至是选择MacMini集群等,都是不错的选择。
这些硬件模型训练性能较弱,但推理能力强悍,对于一些不需要进行模型训练和微调、只需要推理(也就是对话)的场景来说,是个非常不错的选择。例如45万左右成本,就能购买能运行DeepSeek R1满血版模型的Mac Mini集群,相比购买英伟达显卡,能够节省很大一部分成本。但劣势在于Mac M系列芯片并不适合进行模型训练和微调。

采用DeepSeek R1 Distill蒸馏模型:DeepSeek R蒸馏模型组同样推理性能不俗,且蒸馏模型尺寸在1.5B到70B之间,可以适配于任何硬件环境和各类不同的使用需求。
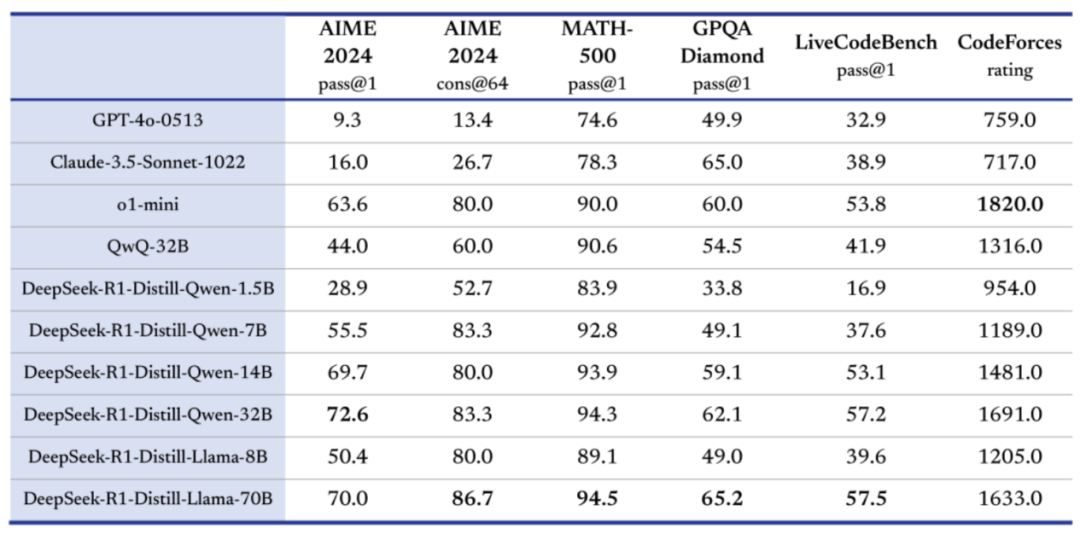
其中各蒸馏模型、各量化版本、各不同使用场景(如模型推理、模型高效微调和全量微调)下模型所需最低配置,可以查看这一文:大模型配置硬件参考自查表
2. 采用KTransformers(Quick Transformers)技术
这是一项由清华大学团队提出的,可以在模型运行过程中灵活的将专家模型加载到CPU上,同时将MLA/KVCache卸载到GPU上,从而深度挖掘硬件性能,实现更低的显存运行更大尺寸的模型。
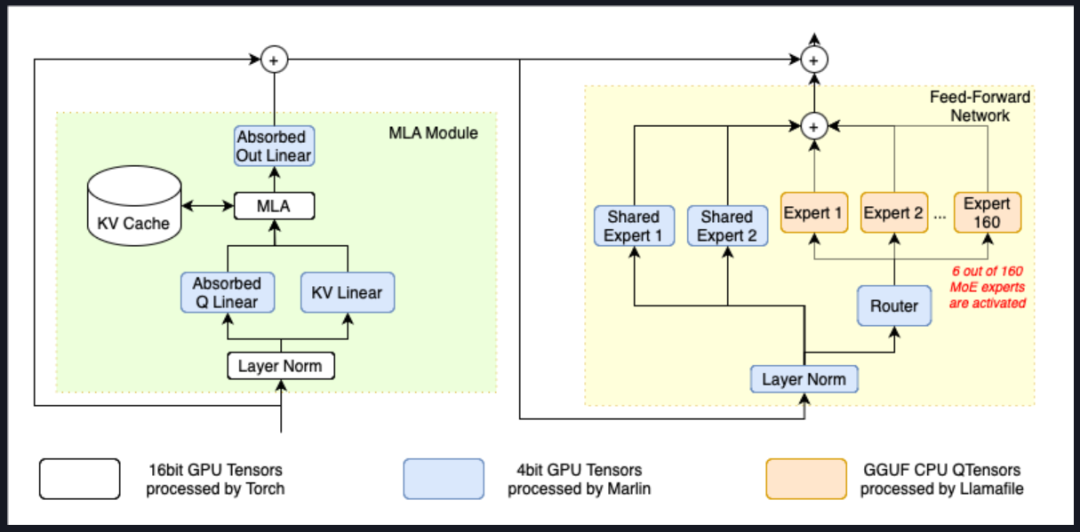
该技术目前的实践效果,可以实现480G内存+13G显存(长尺寸输出或多并发时达到20G显存),即可运行DeepSeek R1 Q_4_K_M量化版模型(类似INT4量化),并且响应速度能够达到15token/s。
大幅降低了传统DeepSeek R1 INT4模型的运行门槛。这也是目前最具价值的DeepSeek R1高性能部署方案。
KTransformers GitHub:https://github.com/kvcache-ai/ktransformers
传统情况下,8卡 A100 GPU服务器才能运行DeepSeek R1 INT4模型,成本接近200万。而480G内存+单卡4090服务器,总成本不到5万。
3. 采用Unsloth动态量化技术
不同于KT将不同的专家加载到CPU上,通过内存分担显存的方法保证R1 Q4KM模型运行。
作为资深量化专家团队,Unsloth团队的技术方案则是在确保模型性能的基础上,更深度的进行模型量化(最多量化到1.58Bit),并且执行不同任务时将激活的专家加载到GPU上,从而压缩模型运行所需硬件条件。
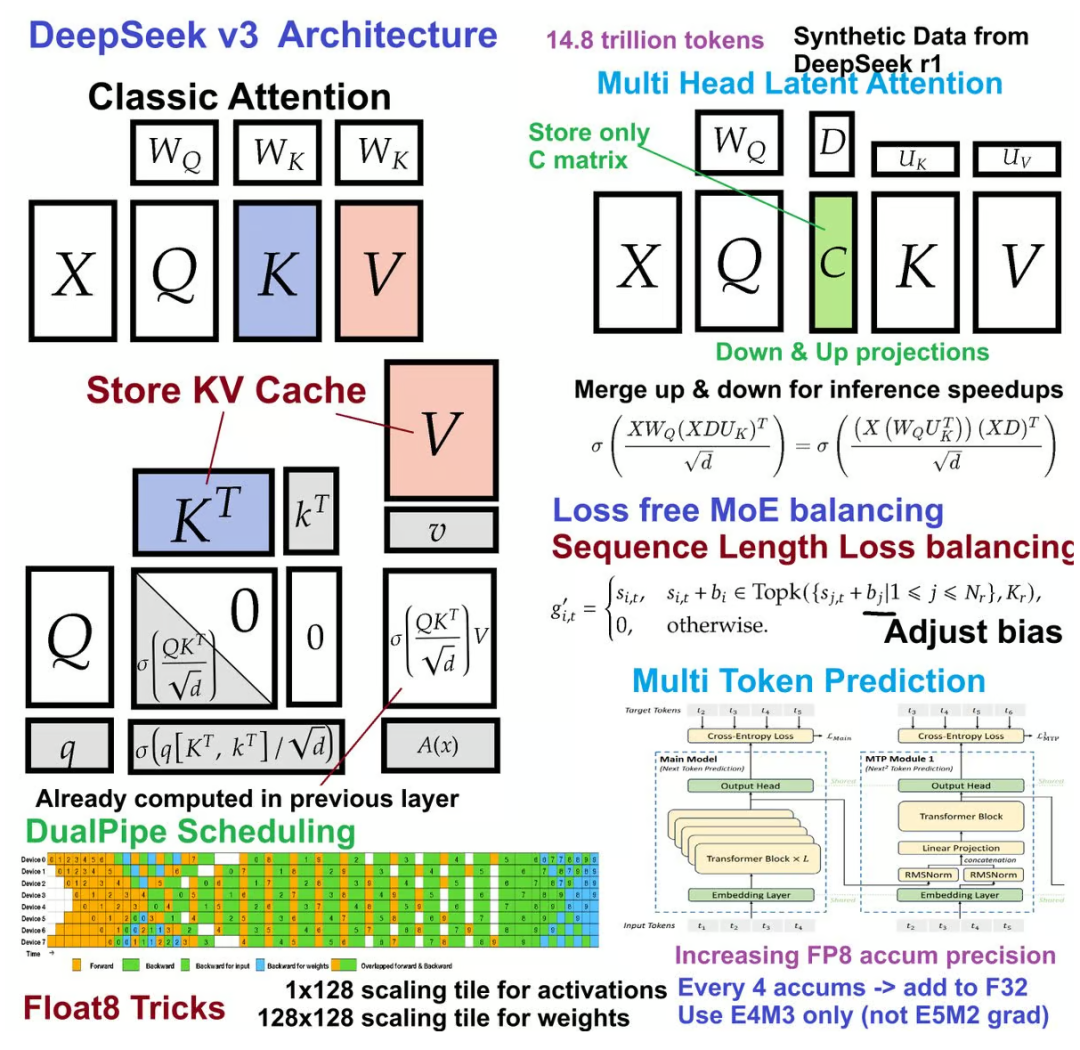
该技术能够实现单卡24G显存运行1.58bit到2.51bit的DeepSeek R1模型,并且提供了一整套动态方案,支持从单卡24G到双卡80G服务器运行动态量化的R1模型,并且对于内存和CPU没有任何要求。
通常意义下量化程度越深,模型效果越差,但由于Unsloth出色的技术能力,导致哪怕是1.58bit量化情况下,量化模型仍能拥有大部分原版模型的能力。
Unsloth主页:https://unsloth.ai/
安装步骤
1. 安装操作系统
建议 Ubuntu24.04,并启用 root 用户,下述所有操作均在 root 用户下进行
cd /root2. 环境预处理
更新系统
# apt update && apt upgrade安装需要的软件
# apt install git build-essential cmake ninja-build apt-transport-https ca-certificates curl gnupg
# curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key | gpg --dearmor -o /usr/share/keyrings/nodesource.gpg
# chmod 644 /usr/share/keyrings/nodesource.gpg
# echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/nodesource.gpg] https://deb.nodesource.com/node_23.x nodistro main" | tee /etc/apt/sources.list.d/nodesource.list
# apt update -y
# apt install nodejs -y安装 conda
# wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
# sh Anaconda3-2024.10-1-Linux-x86_64.sh安装 conda 时需要阅读授权协议,按空格键快速翻页,然后输入 yes 来同意协议,conda 将被安装到 /root/anaconda3 路径。最后在提示 conda init 时输入 yes。
完成 conda 的安装后,需要注销系统并重新登录。重新登录后,命令行的最前面会显示 (base) 字样。
安装 N 卡驱动和 cuda 工具
这里安装的版本是 cuda 12.6,如果需要安装其他版本,请移步 https://developer.nvidia.com/cuda-toolkit-archive
# wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-ubuntu2404.pin
# mv cuda-ubuntu2404.pin /etc/apt/preferences.d/cuda-repository-pin-600
# wget https://developer.download.nvidia.com/compute/cuda/12.6.0/local_installers/cuda-repo-ubuntu2404-12-6-local_12.6.0-560.28.03-1_amd64.deb
# dpkg -i cuda-repo-ubuntu2404-12-6-local_12.6.0-560.28.03-1_amd64.deb
# cp /var/cuda-repo-ubuntu2404-12-6-local/cuda-*-keyring.gpg /usr/share/keyrings/
# apt-get update
# apt-get -y install cuda-toolkit-12-6创建 python 虚拟环境
注意这里必须用 python 3.11 。
# conda create --name ktransformers python=3.11
# conda activate ktransformers
# conda install -c conda-forge libstdcxx-ng安装 pip 依赖
由于 torch 和一些其他的库不支持使用 conda 来进行依赖管理,因此依然需要使用 pip 来安装。这里需要和上面安装的 cuda 工具版本一致,安装对应 cuda 12.6 的 torch
# pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip3 install packaging ninja cpufeature numpy如果需要安装其他版本的 torch,请移步 https://pytorch.org/
安装 flash-attension
这个库需要手动安装编译后的 wheel,手动编译会耗费相当久的时间。flash-attension 同样需要与 cuda 版本以及 python 版本匹配。
# wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp311-cp311-linux_x86_64.whl
# pip install flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp311-cp311-linux_x86_64.whl配置环境变量
# vim .bashrc
# 将以下内容贴到 .bashrc 的最后
export PATH=$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export CUDA_HOME=/usr/local/cuda
export CUDA_PATH=/usr/local/cuda完成这一步后,注销系统并重新登录。
[注意] 这部分的内容,在官方文档中是错误的。
3. 安装配置 KTransformers
下载代码
# git clone https://github.com/kvcache-ai/ktransformers.git
# cd ktransformers
# git submodule init
# git submodule update编译前端代码
# cd ktransformers/website
# npm install @vue/cli
# npm run build
# cd ../../
# pip install .这一步有可能会报错,也有可能是正确的,不论是哪种情况都不用理会,直接往下一步进行。
编译 Python 可执行库
# bash install.sh修复方法即是把 torch 再安装一遍:
# pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126编译 so 文件
# cd ktransformers/ktransformers_ext/cuda
# python setup.py develop将 so 文件拷到 python 依赖中:
# cp -f KTransformersOps.cpython-311-x86_64-linux-gnu.so /root/anaconda3/envs/ktransformers/lib/python3.11/site-packages/KTransformersOps.cpython-311-x86_64-linux-gnu.so[注意] 这一步骤在官方文档中不存在
再次编译 ktransformers
# cd /root/ktransformers
# bash install.sh[注意] 这一步骤在官方文档中不存在
4. 部署模型
这个步骤中,我们选择 DeepSeek-R1-Q4_K_M-GGUF 模型,以便在低配置的机器上得以验证。如果要换用其他模型,步骤是一样的。
建立下载目录
# cd /root/ktransformers
# cd DeepSeek-R1-GGUF
# mkdir DeepSeek-R1-Q4_K_M-GGUF下载模型
从以下链接下载模型并放置到上一步骤中创建的目录里。
#huggingface.co
https://huggingface.co/unsloth/DeepSeek-R1-GGUF?show_file_info=DeepSeek-R1-Q4_K_M%2FDeepSeek-R1-Q4_K_M-00001-of-00009.gguf
#modelscop
https://modelscope.cn/models/unsloth/DeepSeek-R1-GGUF/files
DeepSeek-R1-Q4_K_M-GGUF5. 启动 ktransformers
# cd /root/ktransformers
# python -m ktransformers.local_chat --model_path deepseek-ai/DeepSeek-R1 --gguf_path ./DeepSeek-R1-GGUF/DeepSeek-R1-Q4_K_M-GGUF# pip uninstall flash-attn
# pip install flash_attn重装完毕后再重新启动 ktransformers 。
如果成功启动 ktransformers 后,无法正常对话,提示 module 'KTransformersOps' has no attribute 'gptq_marlin_gemm' 异常,需要重新编译 ktransformers:
# cd /root/ktransformers
# bash install.sh完成后再次启动 ktransformers 即可正常对话。
6. 启动 Restful API
# ktransformers --model_path deepseek-ai/DeepSeek-R1 --gguf_path ./DeepSeek-R1-GGUF/DeepSeek-R1-Q4_K_M-GGUF --port 100027. 启动 Web UI
# ktransformers --model_path deepseek-ai/DeepSeek-R1 --gguf_path ./DeepSeek-R1-GGUF/DeepSeek-R1-Q4_K_M-GGUF --port 10002 --web True成功启动后,通过浏览器访问以下 URL 即可看到 WEB UI 并进行对话:
http://127.0.0.1:10002/web/index.html部署使用体验
测试结果
经过多次测试,我们得到了5.2 tokens/s的生成速度。
这些数据显示,在我们的实验环境中,模型的推理速度显著低于官方宣称14 tokens/s的生成速度。
分析原因
通过对比实验配置与官方推荐的最佳实践,我们发现以下几个关键因素可能导致了性能差异:
CPU性能: 我们的测试平台使用的是Intel Xeon Silver 4310 CPU,而官方文档中提到的理想配置包括第四代至强可扩展处理器,这类处理器集成了高级矩阵扩展指令集(AMX),能够大幅提升计算密集型任务的执行效率。相比之下,Silver系列的处理器在处理能力上存在差距,特别是在需要大量矩阵运算的任务中表现不佳。
内存类型:
在内存方面,我们使用的DDR4内存虽然提供了足够的带宽和容量,但是与最新的DDR5内存相比,在读写速度上有明显的劣势。根据相关测试,DDR5内存的读写速度比DDR4内存高出约2000MB/s,提升幅度在35%~41%之间。这种速度上的差异可能影响到数据加载和处理的速度,进而影响整体的推理效率。GPU型号:
虽然NVIDIA GeForce RTX 3090是一款高性能显卡,但在处理极其庞大的模型时,其24GB的显存限制可能成为瓶颈。相比之下,RTX 4090采用了更先进的架构,能够在相同条件下提供更高的计算能力和更好的能效比。这可能是导致我们在实际测试中未能达到理想推理速率的一个重要原因。
结论和建议
采用KTransformers可以在消费级显卡上部署运行DeepSeek-R1 671B满血版本,对内存占用需求比较高
生成token速度还是比较慢的,个人体验使用下还是可以的
已知限制
只能支持单并发访问
KTransformers部署只能采用Q4量化版本
综合体验一般,建议个人体验用用,如果业务上要使用,估计得部署双机,或者采用 vllm + 8卡4090部署(成本20万+)部署。