音频基础知识:以微信语音为例解释声音数字化的整个流程(ADC)

研究语音AI的方向难免需要接触一些采样率、位深度、PCM, WAV等概念,模数转换(Analog-to-Digital Conversion,简称ADC) 和 数模转换器(DAC)是声音信号处理的重要手段
网上音频相关的知识感觉有点杂乱,本文整理一些基础知识,方便小白阅读理解
声学基础:什么是声音?
声音是由物体的振动产生声波,由声波传递到人耳识别出声音,声波是传递声音信息的重要形式。
声波的产生&传播
简短版的解释是:空气振动产生了声波,然后这个声波再通过类似空气、水、金属等介质进行传播,最后进入我们耳朵被我们听见。
接下来是详细版的解释:我们知道空气实际上是一大堆分子:氧气分子、氮气分子等等,空气中的分子会不断地移动、碰撞,从而在任何一个与空气接触的物质上形成一个静态压强,这个压强取决于空气的密度、温度,且由于万有引力的原因,靠近地球表面的空气被挤压在一起,形成每平方米十万牛顿(力学单位)的压强,这就叫大气压强。
当空气被一个物体(声源)的运动、振动干扰,空气密度会不断变化,当振动物体向外移,将附近的空气分子推开并挤压在一起,会使得此处分子的密度和压强略有增加,形成密部,当振动物体向内移动,空气分子散播开来填充空出的空间,就会产生密度和压强略有下降的疏部,这些压强变化就是我们说的声波。
声波的粒子(比如空气中的各种分子),会沿着波运动的方向向前、向后振荡。一个形象的比喻是将空气比作一条被弹簧连接的高尔夫球链:当最左端的高尔夫球从左边被推到右边,则弹簧将被压缩,进而导致旁边的高尔夫球移动到右边,再导致下一弹簧被压缩,如此往复,沿着这条链传遍所有高尔夫球。这就是声波的传播过程。
 声波的粒子运动
声波的粒子运动
声波三要素
声波的波形图可以完备地描述一段声音,通过波形图,我们就可以知道这段声音是什么样的,包括我们后面要存储、传输、甚至合成一段声音,实质上都是想办法来存储、传输、合成这段声音对应的波形图。有了这个波形图的信息,我们就能在任意时刻、任意地点再把这段声音播放出来。
先来看声波的三个要素:音调、响度和音色。
音调
音调代表的是声音的高低,这个取决于声源振动的频率,即物体1秒内振动的次数,单位是赫兹。频率越大,音调越高。比如往保温瓶里灌开水的时候,它的声音就会逐渐变化。因为在灌的时候,声源是水面上方的空气柱,随着水位的不断升高,空气柱会不断变短,振动不断加快,音调也就越来越高,听起来越来越尖锐。其中人耳能听到的频率范围在20赫兹~20000赫兹。
对应到波形图中,则是对应的波形图的疏密程度,越密说明频率越大,音调越高。
响度
响度,也叫音量,指的是声音的强弱,这个取决于声源振动的幅度(波形图最高点和最低点的距离)以及离声源的距离。
对应到波形图中,最高点和最低点的距离就是振幅,这个距离越大,响度也就越大。分贝是一个衡量响度的指标,响度越大,分贝数就越高。
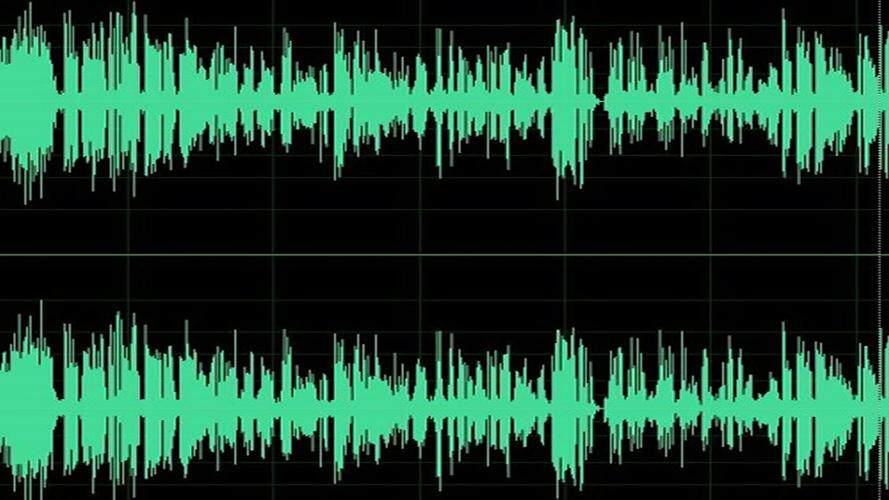
生活中我们会将分贝作为一个衡量声音响度的指标,分贝数越大,响度越高。这么认为倒也没什么问题,但是这里补充一下是:其实分贝并不反映声音的绝对响度,而是以某一个声音为基准,描述声音响度的相对关系。按理说声音强度对应的是声压,但是这个声压的变化范围非常大,肯呢个相差成千上万倍,比如步枪的声压是汽车的声压要大上万倍,所以如果直接用声压来描述响度其实既不直观也不方便。所以就衍生出了“分贝”这个概念:人为地将一个声压定为标准值,然后其他的任何一个声音,都和这个标准值相除,并取结果的对数(以10为底),再乘20,通过这种方式,将一个指数增长的物理量转化为了一个线性增长的物理量。在这种模式下,步枪是171分贝,汽车是80分贝,看上去就直观多了。其中0分贝的标准值是2 \times 10^{-5}Pa(20μPa),相当于3米外一只蚊子在飞。所以0分贝并不是真正的没有声音,甚至也会存负分贝。
各种级别音量的类比
音色
音色则是指声音的品质特点,比如不同的人,即使他们用同样的音调、音量说话,我们听起来也是不一样的。这就是音色的区别。
而对应到波形图中,则体现在波形的差异上,不同发声体的波形是不一样的。它有基频,谐频等等概念。通过一些处理手段获得语谱图并计算出语谱图之间的相似度,以达到声纹识别的目的。(比如识别是不是同一个人在说话等等)
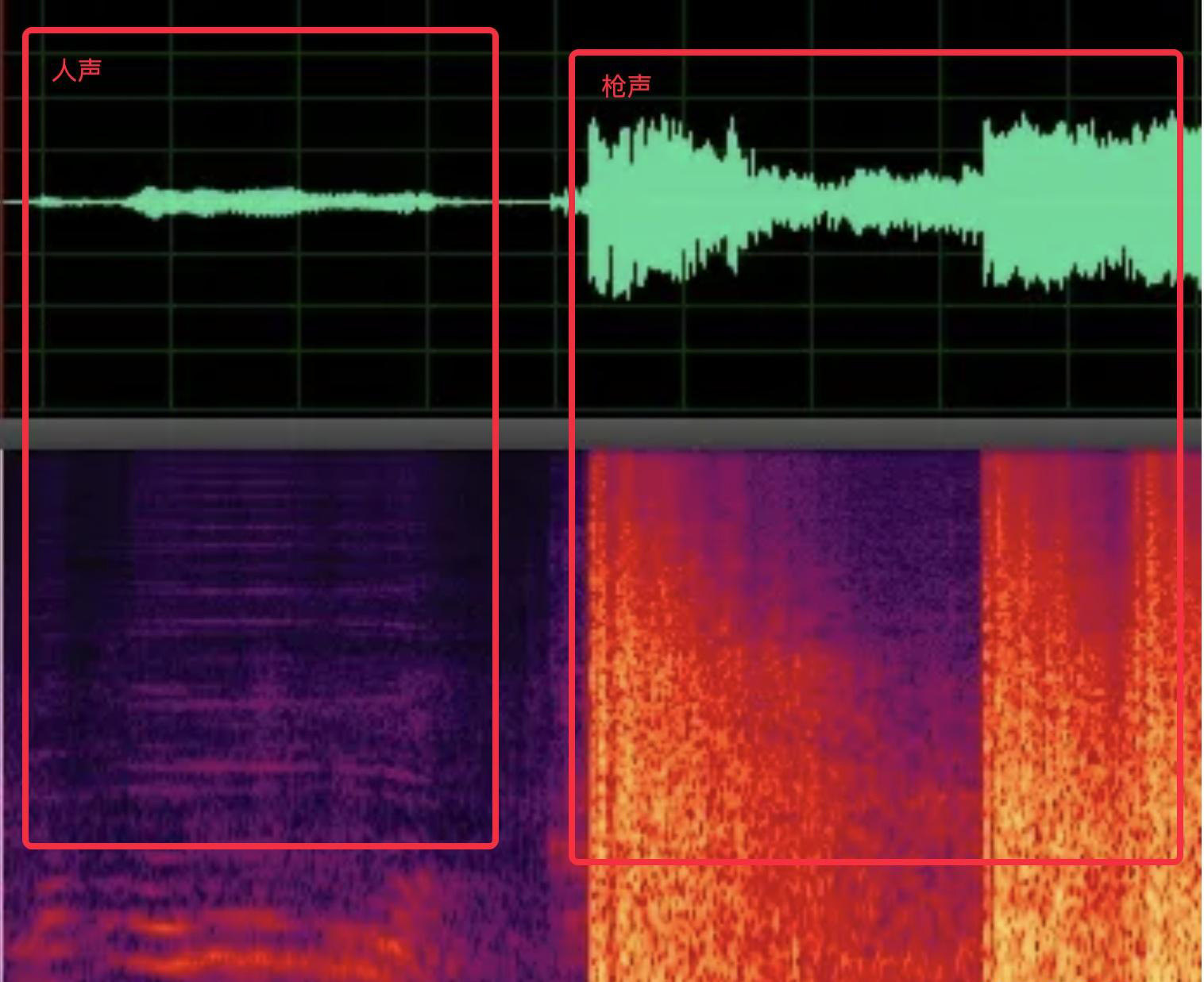 不同音色的声波
不同音色的声波
音频数字化
上面我们了解了自然界的声音是怎么一回事,接下来我们进一步看看计算机是怎么处理声音的。
计算机需要对声音进行数字化,也就是说把现实世界中的声音(比如歌曲、演讲等等)变成计算机里的音频文件(比如忘情水.mp3),主要有三个步骤:采样、量化、编码。接下来我们分别进行解释。
采样
什么叫采样呢?
首先我们要了解两个概念:模拟信号和数字信号。现实世界中的声音是模拟信号,是连续的,而计算机要处理的则是数字信号,是离散的,是一串有限数量的0,1数据流。而采样就是要要把模拟信号转化为数字信号。采样其实是一种近似描述,因为连续的信号是无限的,处理无限的数据不好处理,所以就退而求其次,去进行间隔性的记录,来近似地描述这个事物。
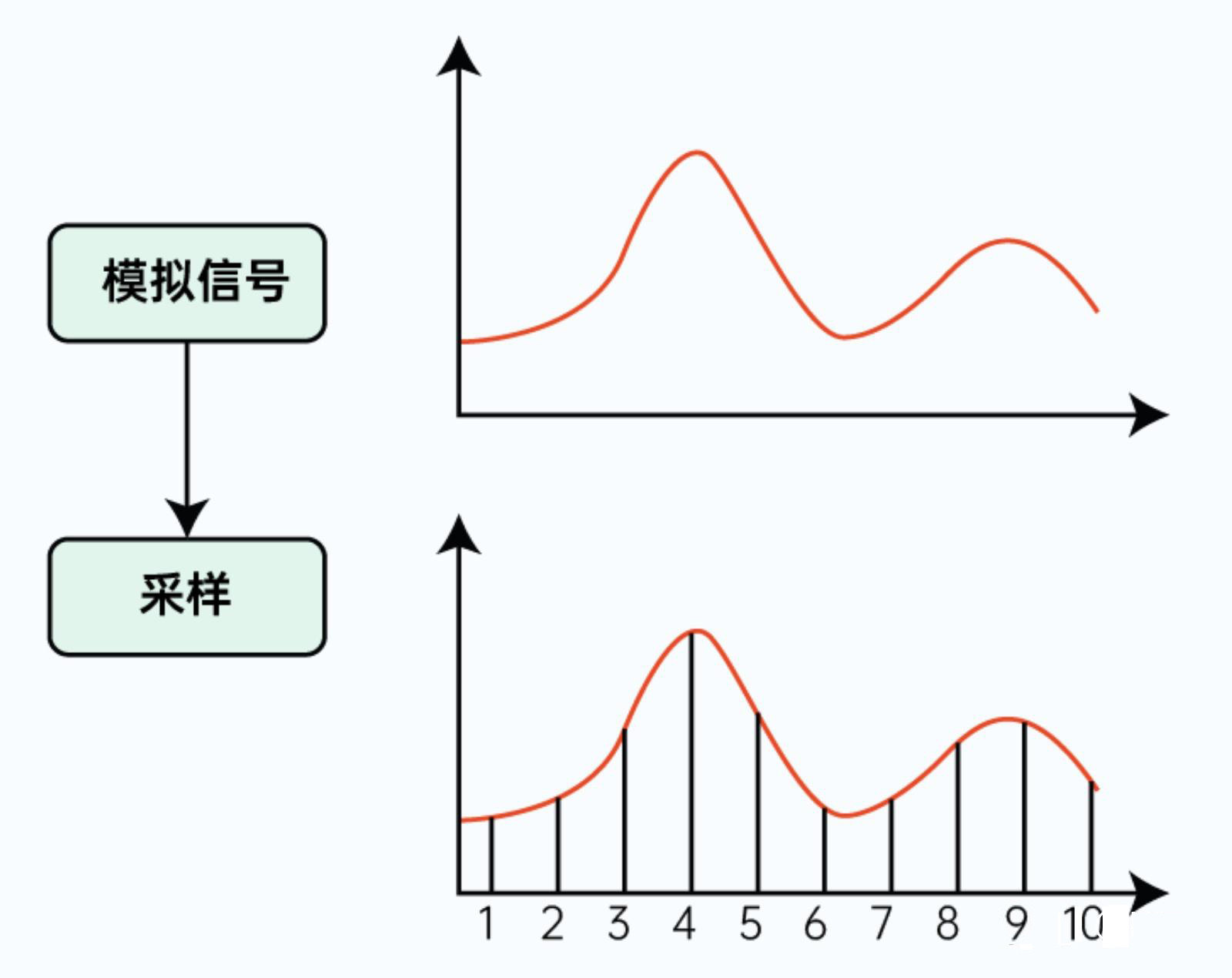
模拟信号和数字信号
举个生活中的例子吧,其实采样就很像“抽查”。比如你是一个中学老师,不做人的校长给你分配了500个学生,当寒假结束时,几百份厚厚的寒假作业交了上来,校长要求你充分评估、了解学生的知识掌握情况。怎么评估呢?理论上最好的方式是把每一个学生的每一页作业都仔细地批改、打分,但是那样可能要花几个星期,这个成本太高了,新学期你还要备课、讲课、布置、批改新的作业,你不能把时间都耗在这上面。所以你退而求其次,你随机抽查50个学生的作业,那么这种抽查就能在一定程度上反映整体学生们的掌握情况。
音频中的采样也是这个意思,在音频处理中,采样是指以一定的时间间隔对音频信号进行测量和记录采样率是指每秒钟进行多少次采样。比如像采样率是44.1K,意思就是每秒采集441000个样本点,就像是每1/441000秒抽查一个模拟信号点。每一次采样都记录下了原始声波在某一刻的状态。
所以其实这个采样率就很像图像的像素,单位面积像素越高,图片就越清晰,采样率也是这样。那么这个采样率应该定多少好呢?信息论里有个奈奎斯特定理指出:
当采样频率高于信号中最高频率的两倍时,采样后的数字信号就能完整保留原始信号中的信息。
结合我们前面说的人耳最高能感知到的频率是20K,所以主流采样率中的44.1K,48K理论上已经能满足人耳的需求了。
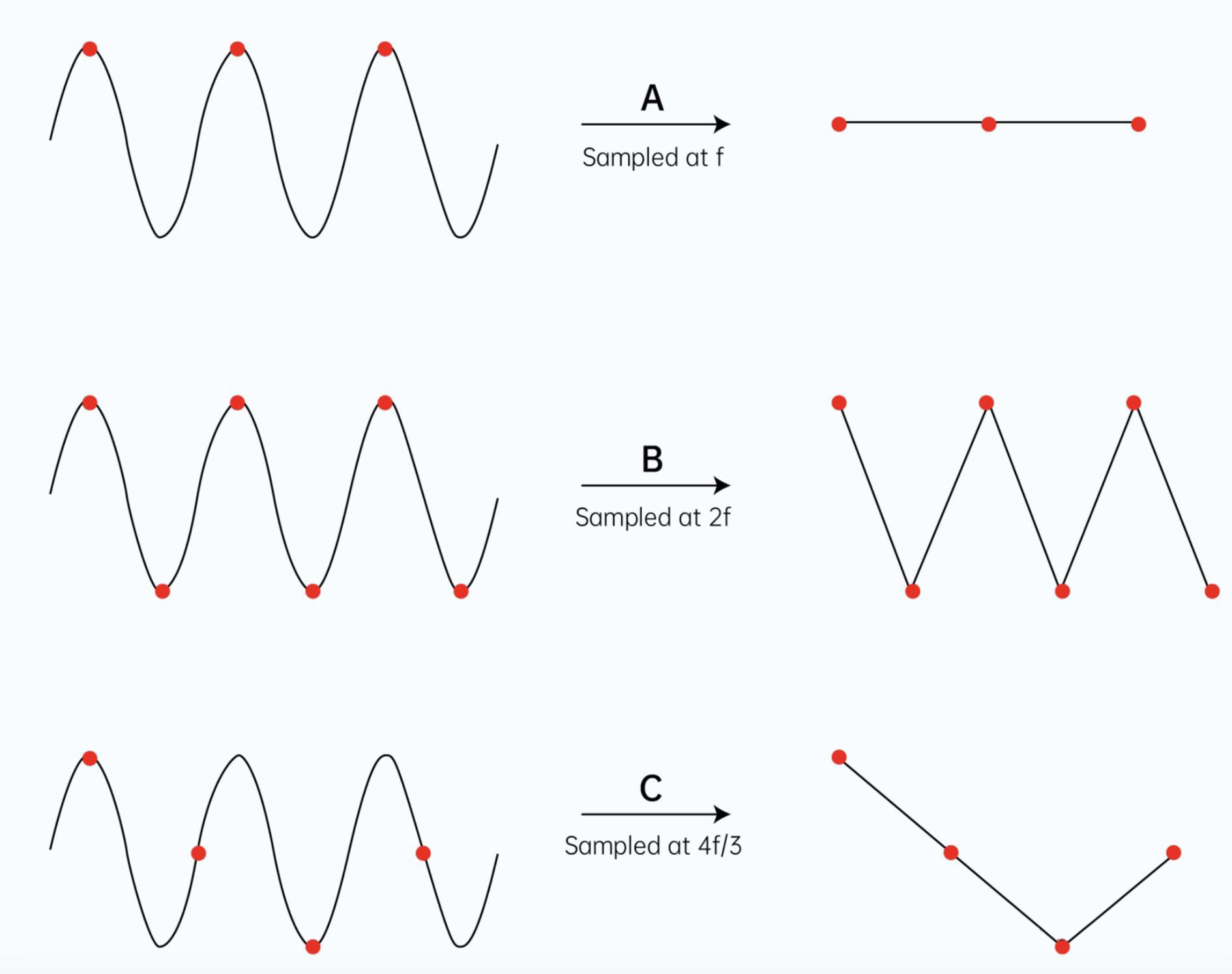 不同采样率采集到的声波信息完整度不一样
不同采样率采集到的声波信息完整度不一样
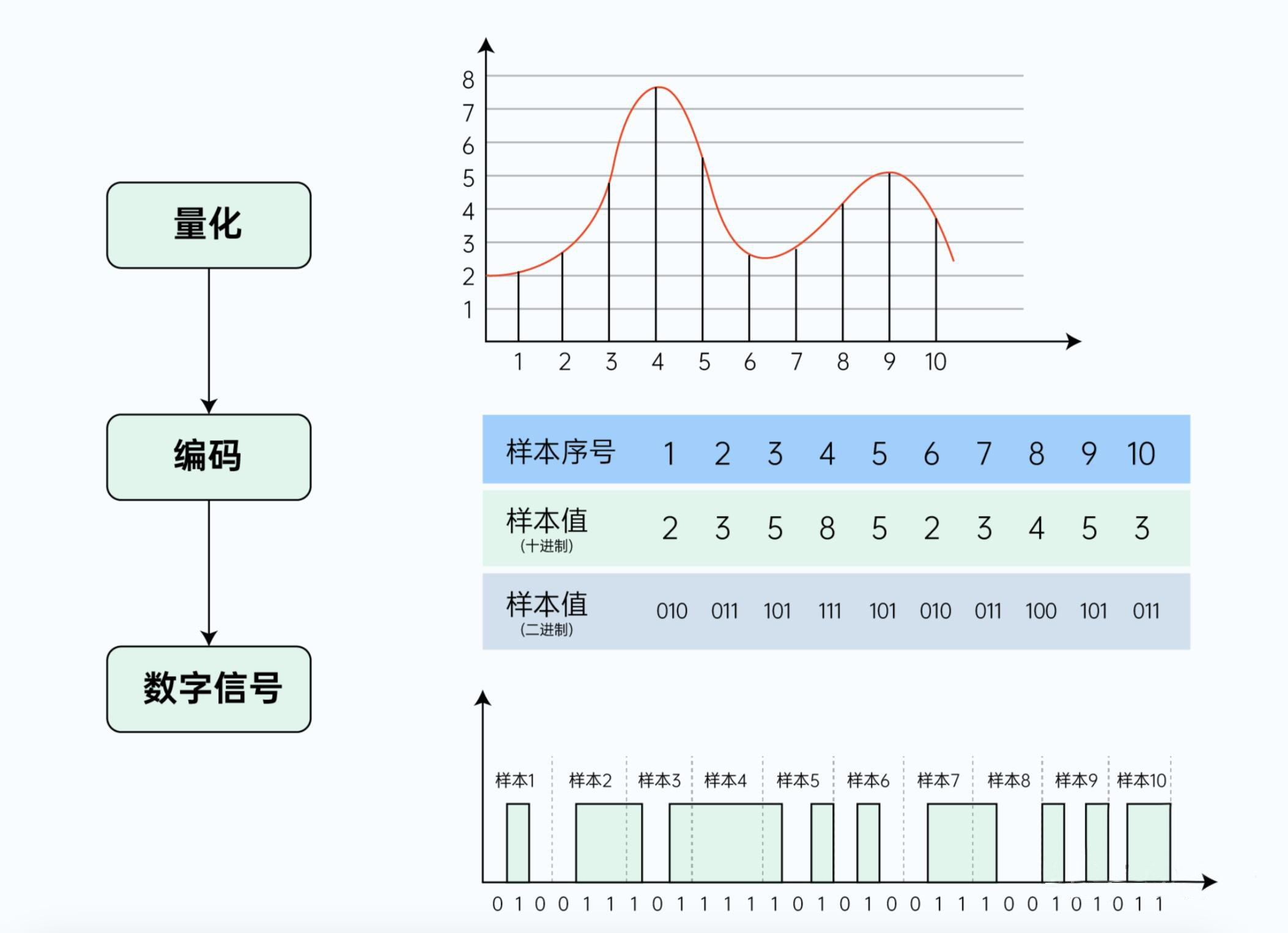
量化
量化这个词就顾名思义了,就是要量化这个音频采样点,给他一个有含义的数字。这个量化就有精度的概念在里面。再打个比方,还是上面抽查作业的例子,量化就好比对你抽查的每一本作业进行打分。那最简单的就是你可以分为两类:0分和1分,0 分是不及格,1分是及格。但这种就比较粗暴、粗糙,可能最后评估效果也不是那么好,所以你可以用10分制来量化,那这里就能区分一般、比较好、非常好这些程度,再进一步地,你可以用百分制,里面各个题目根据难易程度、重要程度有个对应得分值,最后计算出一个百分之的分数,这个就能更精确地反映出他的掌握程度。
那么音频中的这个也是一样的。对于采集到的数据,我们也要一个值去表示它,这个就是音频文件中位深度的概念,比如16位就代表2的16次方,也就是65535制的值区间。
数字信号采样后量化
编码
编码就是将上面的量化值,转化为二进制字节序列(比如下图中的样本值)。经过这个环节转化后,我们就得到了一串“0”, “1”形式的二进制字节序列,至此,我们就获得了计算机可以“理解”、处理的数字化数据了。这样的数据叫做PCM数据(Pulse Code Modulation),这个是最原始的裸数据,在实际的存储、传输中,我们往往会根据各种编码算法对这个数据再做进一步压缩,比如我们熟悉的mp3, wav等等都是其中的一些编码算法。
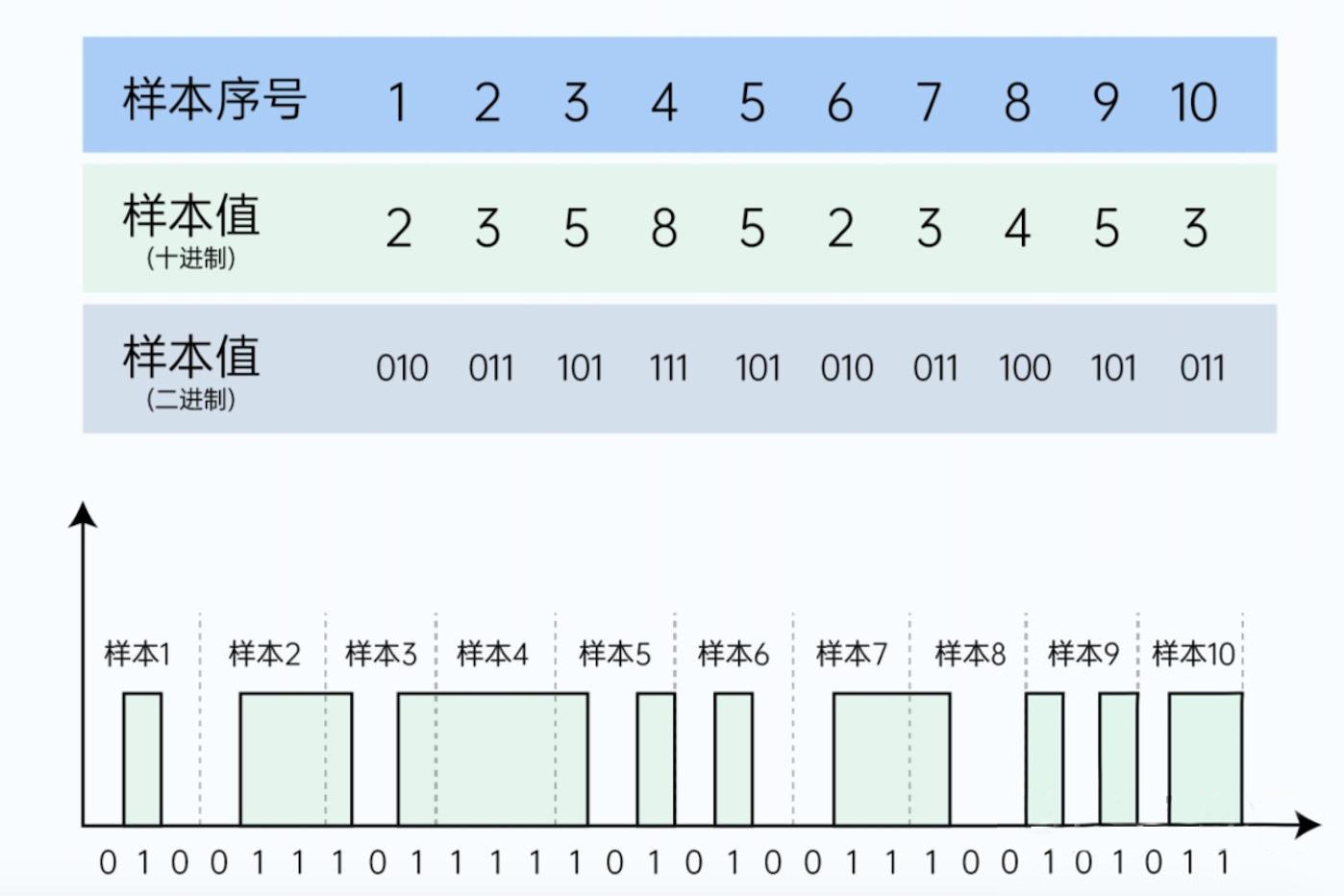 声音编码
声音编码
现实案例:微信语音
最后我们以小明用微信发了一段语音,然后又自己听了一遍自己的录音这个事情为例梳理一下音频数字化的整个流程。

第一步 声带发声
当小明张嘴说话时,他的声带会振动产生声波,之后经过声道,声道会起到滤波器的作用,对频谱进行修正,最后通过张开的嘴将声波传播出去。
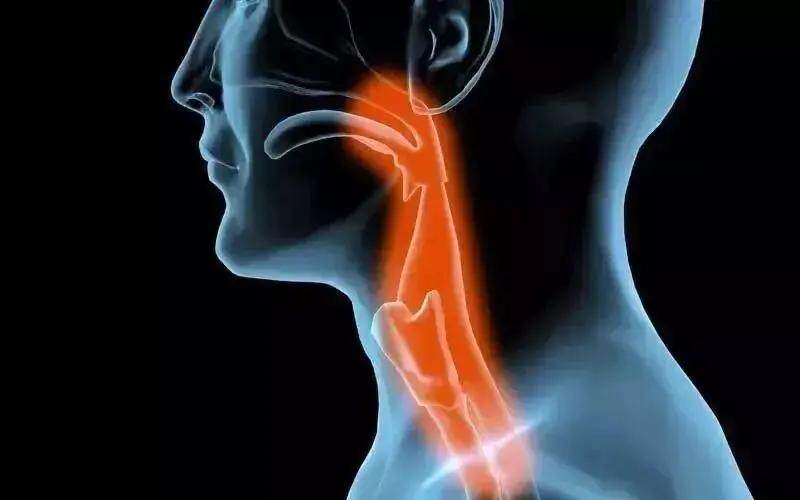
第二步 手机麦克风接收模拟信号
传播出来的声波到达手机麦克风后会被转化成电信号。注意这个转化出来的电信号也是模拟信号,是连续不断的电压信号。
手机麦克风一般是电容麦克风。当小明的话传到手机麦克风时,声波的振动会引起麦克风振膜的振动,从而改变了振膜和基板的距离,进而会导致电容的变化,当距离变小时,电容增大,距离变大时,电容减小。电容的变化经过后续的处理电路会转化为连续变化的电信号(模拟信号)。
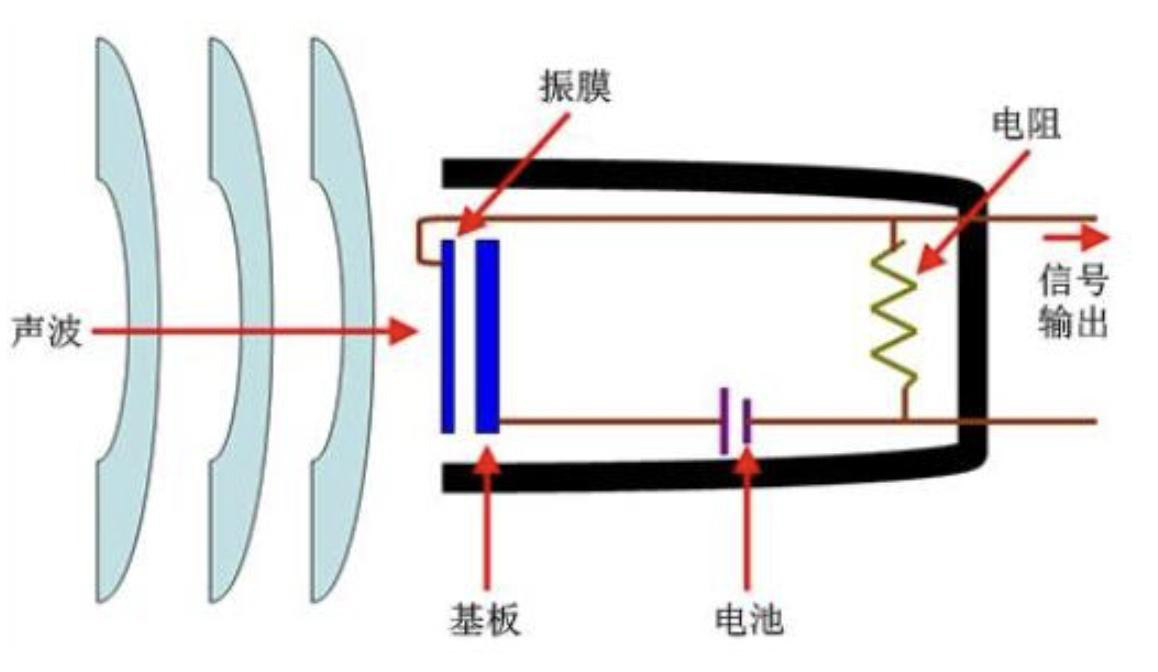 手机麦克风接收模拟信号
手机麦克风接收模拟信号
第三步 声卡进行模数转化
我们的电脑、手机里都会内置一种叫声卡的硬件,在这一步声卡会进行模数转化,即将模拟信号(连续变化的电信号)转化为数字信号。我们上面说的采样、量化、编码就发生在这一步,通过这样的模数转化后,音频就成了一串0,1的二进制数据。
声卡模数转化
第四步 存储设备
微信会将我们的聊天记录等文件存在我们的手机端(所以用得越久,微信占用的空间就越大),所以刚才的数字信号会以文件的形式存储在我们手机的硬盘里(手机的硬盘常常被称为内存),这样无论我们重启手机或者断开网络,我们都可以读取、播放这些音频。如果你断开网络并选一条手机里的语音,会发现它可以正常播放,这就说明它是存在本地而不是远程服务器,否则的话就需要通过网络传输才能获得数据。
第五步 声卡进行数模转换
点击这条录音后,微信程序就会从手机硬盘里读取出对应的音频文件(一堆0101的二进制音频数据),然后通过操作系统将数据送给声卡,进行与第二步相反的数模转化,即通过声卡中的D/A转化器将数字信号(一堆0101的二进制数据)转为模拟信号(连续变化的电信号)。
第六步 手机扬声器
声卡转化出来的模拟信号会通过扬声器转化为声波,下图是一个典型的手机扬声器结构,主要有四个组件:磁铁、线圈、振膜、支架。

典型的手机扬声器结构
经声卡转化后的连续变化的电信号经过铜线圈时,线圈内会产生一个临时感应磁场,此时临时磁场和磁铁的永久磁场则会相互作用,而线圈及包裹着线圈的振膜就会随之移动,随着电流的不断变化,线圈和振膜的位置也会不断变化(其中支架是起到保护和稳定振膜的作用)。在这个过程中,移动的振膜就是声源,会引起周围空气的波动,产生对应的声波。
感应线圈振膜移动产生声波
第七步 人耳感知
扬声器产生的声波通过空气传到人耳,耳膜会随之振动并带动听小骨运动,敲击耳蜗(就像在打鼓一样),图片右边像蜗牛壳一样的结构就是耳蜗,里面充满了液体,在敲击下耳蜗里的液体会震荡,耳蜗里遍布着毛细胞,当液体震荡时,毛细胞会产生神经电信号,经由听觉神经,进入我们的大脑,再由我们的大脑去解析识别声音的含义。
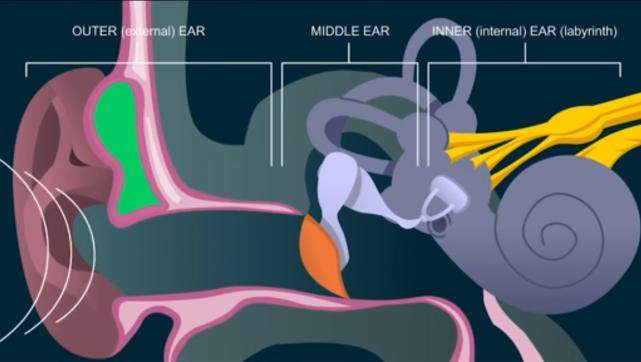 人耳感知声波过程
人耳感知声波过程
至此,整个流程就结束了。