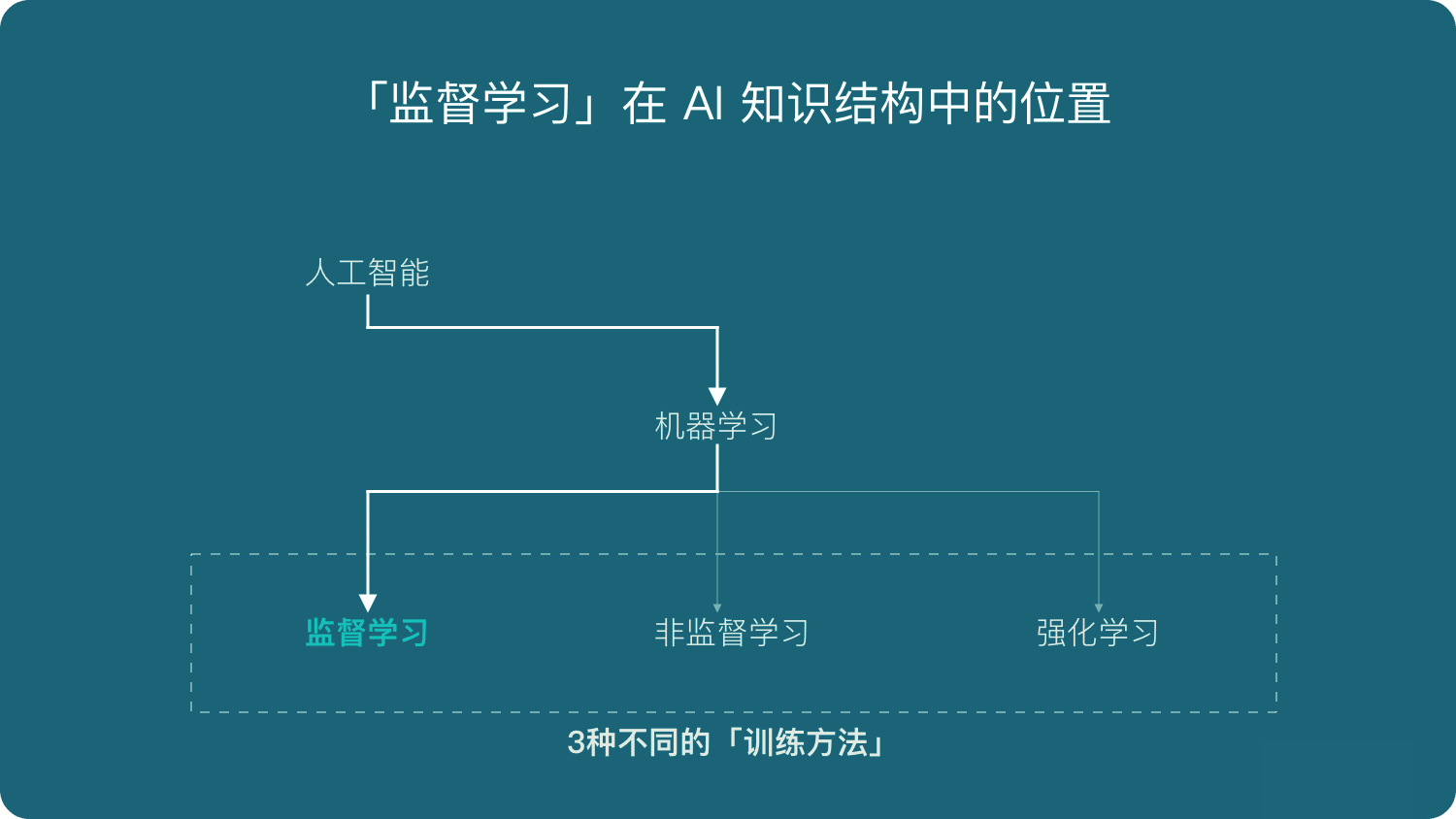
监督学习 | Supervised learning
什么是监督学习?

监督学习是机器学习中的一种训练方式/学习方式:
监督学习需要有明确的目标,很清楚自己想要什么结果。比如:按照“既定规则”来分类、预测某个具体的值…
监督并不是指人站在机器旁边看机器做的对不对,而是下面的流程:
选择一个适合目标任务的数学模型
先把一部分已知的“问题和答案”(训练集)给机器去学习
机器总结出了自己的“方法论”
人类把”新的问题”(测试集)给机器,让他去解答
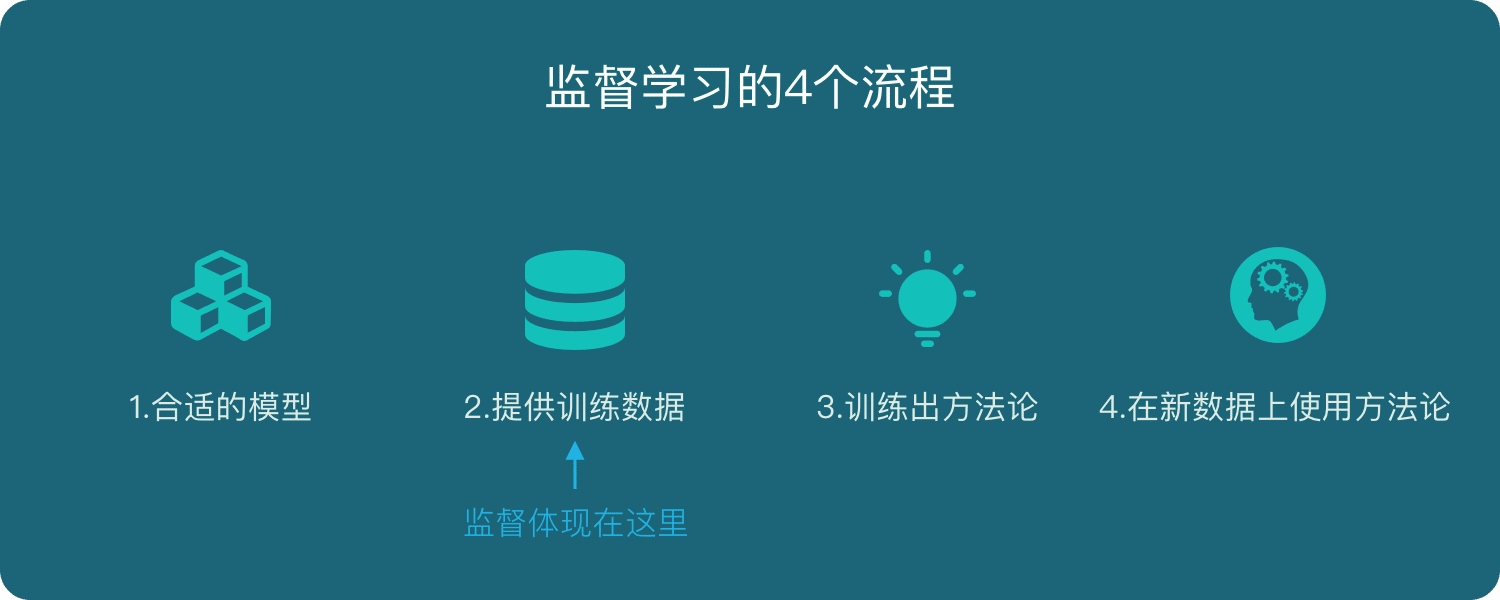 监督学习的4个流程
监督学习的4个流程
上面提到的问题和答案只是一个比喻,假如我们想要完成文章分类的任务,则是下面的方式:
选择一个合适的数学模型
把一堆已经分好类的文章和他们的分类给机器
机器学会了分类的“方法论”
机器学会后,再丢给他一些新的文章(不带分类),让机器预测这些文章的分类
监督学习的2个任务:回归、分类
监督学习有2个主要的任务:
回归
分类
回归:预测连续的、具体的数值。比如:支付宝里的芝麻信用分数(下面有详细讲解)
分类:对各种事物分门别类,用于离散型(什么是离散?)预测。比如:
 监督学习的2个任务:回归、分类
监督学习的2个任务:回归、分类
“回归”案例:芝麻信用分是怎么来的?

下面要说的是个人信用评估方法——FICO。
他跟芝麻信用类似,用来评估个人的信用状况。FICO 评分系统得出的信用分数范围在300~850分之间,分数越高,说明信用风险越小。
下面我们来模拟一下 FICO 的发明过程,这个过程就是监督学习的回归。
步骤1:构建问题,选择模型
我们首先找出个人信用的影响因素,从逻辑上讲一个人的体重跟他的信用应该没有关系,比如我们身边很讲信用的人,有胖子也有瘦子。
而财富总额貌似跟信用有关,因为马云不讲信用的损失是非常巨大的,所以大家从来没有听说马云会不还信用卡!而一个乞丐不讲信用的损失是很小的,这条街混不下去了换一条街继续。
所以根据判断,找出了下面5个影响因素:
付款记录
账户总金额
信用记录跨度(自开户以来的信用记录、特定类型账户开户以来的信用记录…)
新账户(近期开户数目、特定类型账户的开户比例…)
信用类别(各种账户的数目)
这个时候,我们就构建了一个简单的模型:

f 可以简单理解为一个特定的公式,这个公式可以将5个因素跟个人信用分形成关联。
我们的目标就是得到 f 这个公式具体是什么,这样我们只要有了一个人的这5种数据,就可以得到一个人的信用分数了。
步骤2:收集已知数据
为了找出这个公式 f,我们需要先收集大量的已知数据,这些数据必须包含一个人的5种数据和他/她的信用状态(把信用状态转化为分数)。
我们把数据分成几个部分,一部分用来训练,一部分用来测试和验证。

步骤3:训练出理想模型
有了这些数据,我们通过机器学习,就能”猜测”出这5种数据和信用分数的关系。这个关系就是公式 f。
然后我们再用验证数据和测试数据来验证一下这个公式是否 OK。
测试验证的具体方法是:
将5种数据套入公式,计算出信用分
用计算出来的信用分跟这个人实际的信用分(预先准备好的)进行比较
评估公式的准确度,如果问题很大再进行调整优化
步骤4:对新用户进行预测
当我们想知道一个新用户的信用状况时,只需要收集到他的这5种数据,套进公式 f 计算一遍就知道结果了!
好了,上面就是一个跟大家息息相关的回归模型,大致思路就是上面所讲的思路,整个过程做了一些简化,如果想查看完整的过程,可以查看《机器学习-机器学习实操的7个步骤》
“分类”案例:如何预测离婚
美国心理学家戈特曼博士用大数据还原婚姻关系的真相,他的方法就是分类的思路。
戈特曼博士在观察和聆听一对夫妻5分钟的谈话后,便能预测他们是否会离婚,且预测准确率高达94%!他的这项研究还出了一本书《幸福的婚姻》(豆瓣8.4分)。
步骤1:构建问题,选择模型
戈特曼提出,对话能反映出夫妻之间潜在的问题,他们在对话中的争吵、欢笑、调侃和情感表露创造了某种情感关联。通过这些对话中的情绪关联可以将夫妻分为不同的类型,代表不同的离婚概率。
步骤2:收集已知数据
研究人员邀请了700对夫妻参与实验。他们单独在一间屋子里相对坐下,然后谈论一个有争论的话题,比如金钱和性,或是与姻亲的关系。默里和戈特曼让每一对夫妻持续谈论这个话题15分钟,并拍摄下这个过程。观察者看完这些视频之后,就根据丈夫和妻子之间的谈话给他们打分。

步骤3:训练出理想模型
戈特曼的方法并不是用机器学习来得到结果,不过原理都是类似的。他得到的结论如下:
首先,他们将夫妻双方的分数标绘在一个图表上,两条线的交叉点就可以说明婚姻能否长久稳定。如果丈夫或妻子持续得负分,两人很可能会走向离婚。重点在于定量谈话中正负作用的比率。理想中的比率是5∶1,如果低于这个比例,婚姻就遇到问题了。最后,将结果放在一个数学模型上,这个模型用差分方程式凸显出成功婚姻的潜在特点。
戈特曼根据得分,将这些夫妻分成5组:

幸福的夫妻:冷静、亲密、相互扶持、关系友好。他们更喜欢分享经验。
无效的夫妻:他们尽最大努力避免冲突,只是通过积极回应对方的方式。
多变的夫妻:他们浪漫而热情,可争论异常激烈。他们时而稳定时而不稳定,可总的来说不怎么幸福。
敌对的夫妻:一方不想谈论某件事,另一方也同意,所以,两者之间没有交流。
彼此无感的夫妻:一方兴致勃勃地想要争论一番,可另一方对讨论的话题根本不感兴趣。
该数学模型呈现了两种稳定型夫妻(关系和谐的夫妻和关系不和谐的夫妻)和两种不稳定型夫妻(敌对夫妻和无感夫妻)之间的区别。而据预测,不稳定的夫妻可能会一直保持婚姻关系,尽管他们的婚姻不稳定。
步骤4:对新用户进行预测
12年以来,每隔一两年,默里和戈特曼都会与参与研究的那700对夫妻交流。两个人的公式对离婚率的预测达到了94%的准确率。
主流的监督学习算法
百科介绍
百度百科(详情)
监督学习是指:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。这就要求学习算法是在一种“合理”的方式从一种从训练数据到看不见的情况下形成。
维基百科(详情)
监督学习是学习函数的机器学习任务,该函数基于示例输入 – 输出对将输入映射到输出。它推断出一个函数标记的训练数据由一组训练样例组成。在监督学习,每个实施例是一个对由输入物体(通常为矢量)和期望的输出值的(也称为监控信号)。监督学习算法分析训练数据并产生推断函数,该函数可用于映射新示例。最佳方案将允许算法正确地确定看不见的实例的类标签。这要求学习算法以“合理”的方式从训练数据推广到看不见的情况。