支持向量机 ( Support Vector Machine | SVM)
什么是支持向量机?
支持向量机可能是最流行和最受关注的机器学习算法之一。
超平面是分割输入变量空间的线。在SVM中,选择超平面以最佳地将输入变量空间中的点与它们的类(0级或1级)分开。在二维中,您可以将其视为一条线,并假设我们的所有输入点都可以被这条线完全分开。SVM学习算法找到导致超平面最好地分离类的系数。
 支持向量机
支持向量机
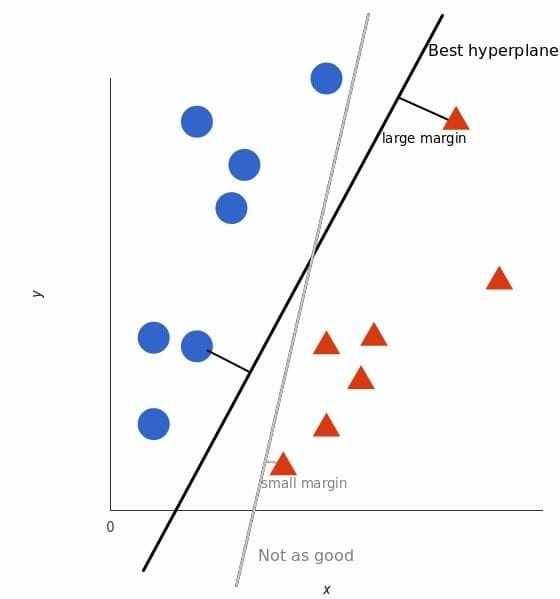
超平面与最近数据点之间的距离称为边距。可以将两个类分开的最佳或最佳超平面是具有最大边距的线。只有这些点与定义超平面和分类器的构造有关。这些点称为支持向量。它们支持或定义超平面。实际上,优化算法用于找到使裕度最大化的系数的值。
SVM可能是最强大的开箱即用分类器之一,值得尝试使用您的数据集。
支持向量机的基础概念可以通过一个简单的例子来解释。让我们想象两个类别:红色和蓝色,我们的数据有两个特征:x 和 y。我们想要一个分类器,给定一对(x,y)坐标,输出仅限于红色或蓝色。我们将已标记的训练数据列在下图中:
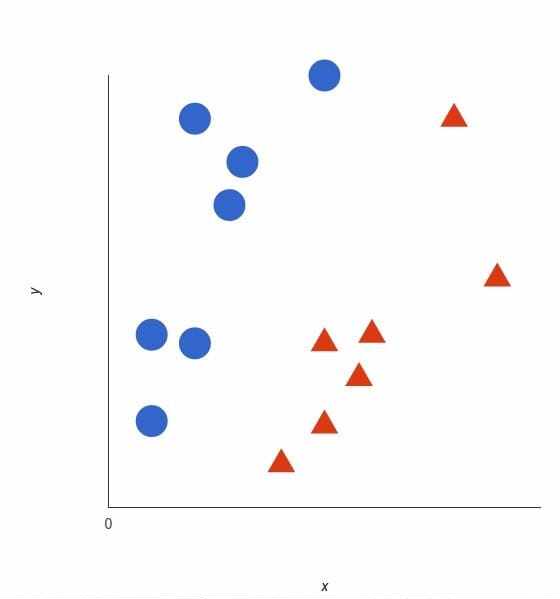
支持向量机会接受这些数据点,并输出一个超平面(在二维的图中,就是一条线)以将两类分割开来。这条线就是判定边界:将红色和蓝色分割开。
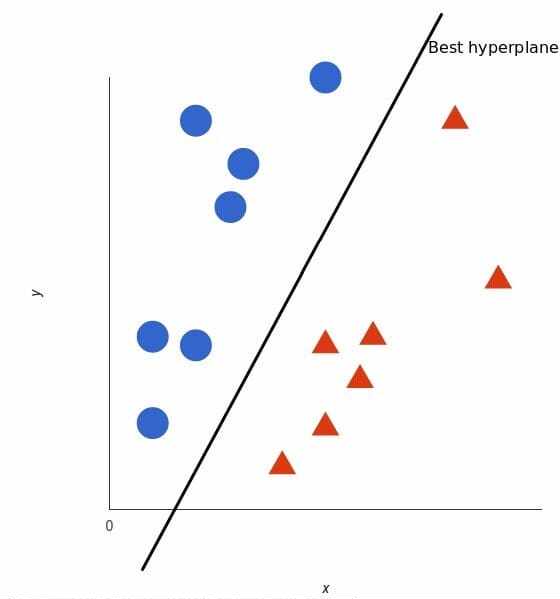
但是,最好的超平面是什么样的?对于 SVM 来说,它是最大化两个类别边距的那种方式,换句话说:超平面(在本例中是一条线)对每个类别最近的元素距离最远。
SVM的优缺点
优点:
可以解决高维问题,即大型特征空间;
解决小样本下机器学习问题;
能够处理非线性特征的相互作用;
无局部极小值问题;(相对于神经网络等算法)
无需依赖整个数据;
泛化能力比较强;
缺点:
当观测样本很多时,效率并不是很高;
对非线性问题没有通用解决方案,有时候很难找到一个合适的核函数;
对于核函数的高维映射解释力不强,尤其是径向基函数;
常规SVM只支持二分类;
对缺失数据敏感;
百科介绍
百度百科(详情)
支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
在机器学习中,支持向量机(SVM,还支持矢量网络)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。
维基百科(详情)
在机器学习中,支持向量机(SVM)是具有相关学习算法的监督学习模型,其分析用于分类和回归分析的数据。给定一组训练示例,每个示例标记为属于两个类别中的一个或另一个,SVM训练算法构建一个模型,将新示例分配给一个类别或另一个类别,使其成为非概率二元线性分类器。SVM模型是将示例表示为空间中的点,映射使得单独类别的示例除以尽可能宽的明确间隙。然后将新的示例映射到同一空间,并根据它们落在哪个边缘预测属于一个类别。
除了执行线性分类之外,SVM还可以使用所谓的内核技巧有效地执行非线性分类,将其输入隐式映射到高维特征空间。