随机森林 | Random Forest
什么是随机森林?

随机森林是一种由决策树构成的集成算法,他在很多情况下都能有不错的表现。
本文将介绍随机森林的基本概念、4 个构造步骤、4 种方式的对比评测、10 个优缺点和 4 个应用方向。
随机森林属于 集成学习 中的 Bagging(Bootstrap AGgregation 的简称) 方法。如果用图来表示他们之间的关系如下:

决策树 – Decision Tree
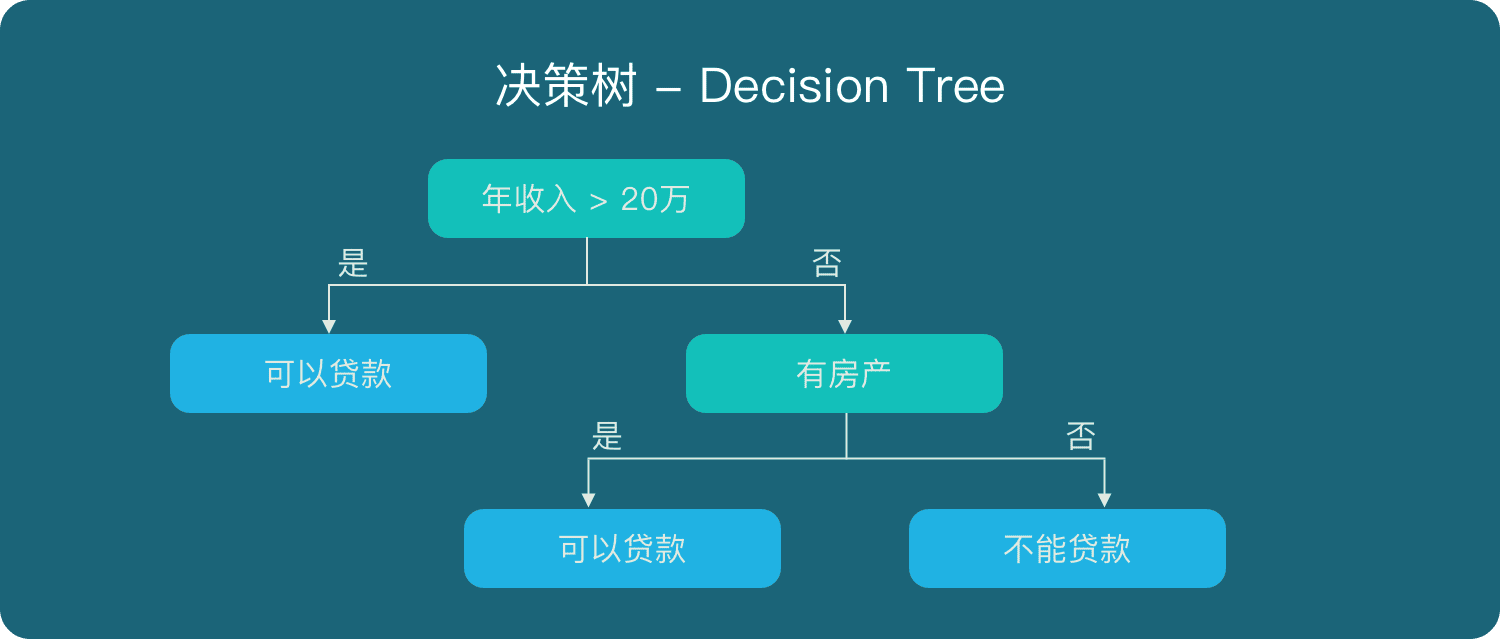
在解释随机森林前,需要先提一下决策树。决策树是一种很简单的算法,他的解释性强,也符合人类的直观思维。这是一种基于if-then-else规则的有监督学习算法,上面的图片可以直观的表达决策树的逻辑。
了解详情:《一文看懂决策树 – Decision tree(3个步骤+3种典型算法+10个优缺点)》
随机森林 – Random Forest | RF
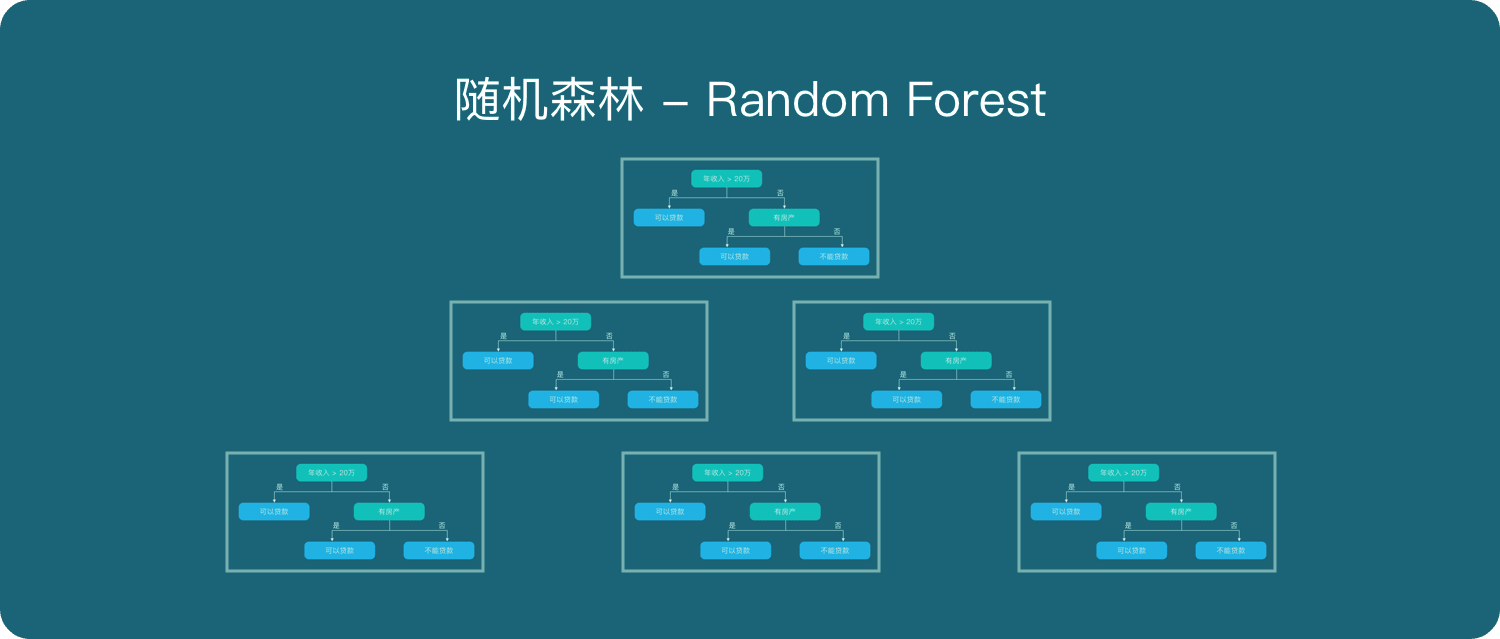
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
构造随机森林的 4 个步骤

一个样本容量为N的样本,有放回的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
随机森林的优缺点
优点
它可以出来很高维度(特征很多)的数据,并且不用降维,无需做特征选择
它可以判断特征的重要程度
可以判断出不同特征之间的相互影响
不容易过拟合
训练速度比较快,容易做成并行方法
实现起来比较简单
对于不平衡的数据集来说,它可以平衡误差。
如果有很大一部分的特征遗失,仍可以维持准确度。
缺点
随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
随机森林 4 种实现方法对比测试
随机森林是常用的机器学习算法,既可以用于分类问题,也可用于回归问题。本文对 scikit-learn、Spark MLlib、DolphinDB、XGBoost 四个平台的随机森林算法实现进行对比测试。评价指标包括内存占用、运行速度和分类准确性。
测试结果如下:
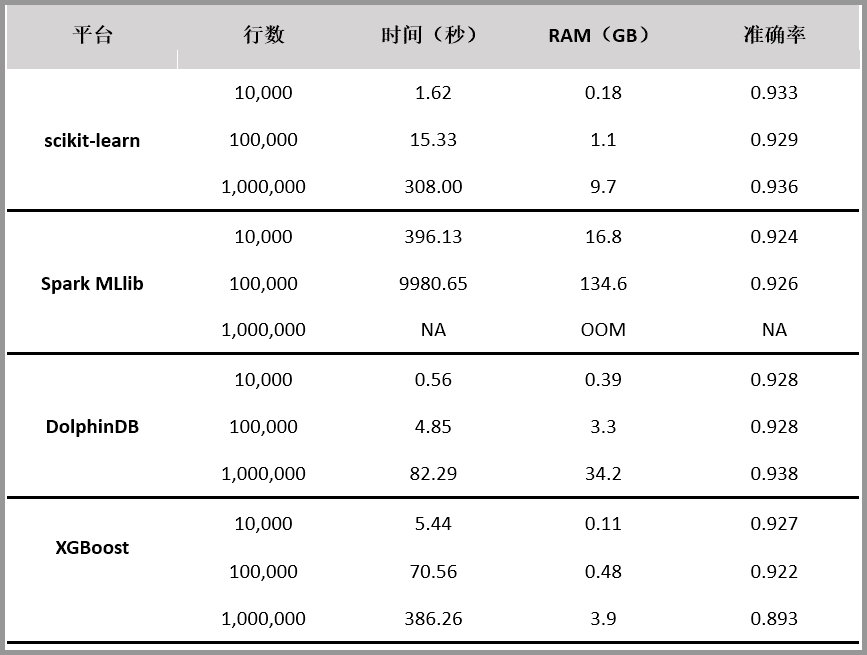
测试过程及说明忽略,感兴趣的可以查看原文《随机森林算法 4 种实现方法对比测试:DolphinDB 速度最快,XGBoost 表现最差》
随机森林的 4 个应用方向

随机森林可以在很多地方使用:
对离散值的分类
对连续值的回归
无监督学习聚类
异常点检测
百科介绍
百度百科(详情)
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。
维基百科(详情)
随机森林或随机决策森林是用于分类,回归和其他任务的集成学习方法,其通过在训练时构建多个决策树并输出作为类的模式(分类)或平均预测(回归)的类来操作。个别树木。随机决策森林纠正决策树过度拟合其训练集的习惯。