计算机视觉 | ( Computer Vision | CV)

计算机视觉(Computer Vision)是人工智能领域的一个重要分支。它的目的是:看懂图片里的内容。
本文将介绍计算机视觉的基本概念、实现原理、8 个任务和 4 个生活中常见的应用场景。
计算机视觉为什么重要?
人的大脑皮层, 有差不多 70% 都是在处理视觉信息。 是人类获取信息最主要的渠道,没有之一。
在网络世界,照片和视频(图像的集合)也正在发生爆炸式的增长!
下图是网络上新增数据的占比趋势图。灰色是结构化数据,蓝色是非结构化数据(大部分都是图像和视频)。可以很明显的发现,图片和视频正在以指数级的速度在增长。
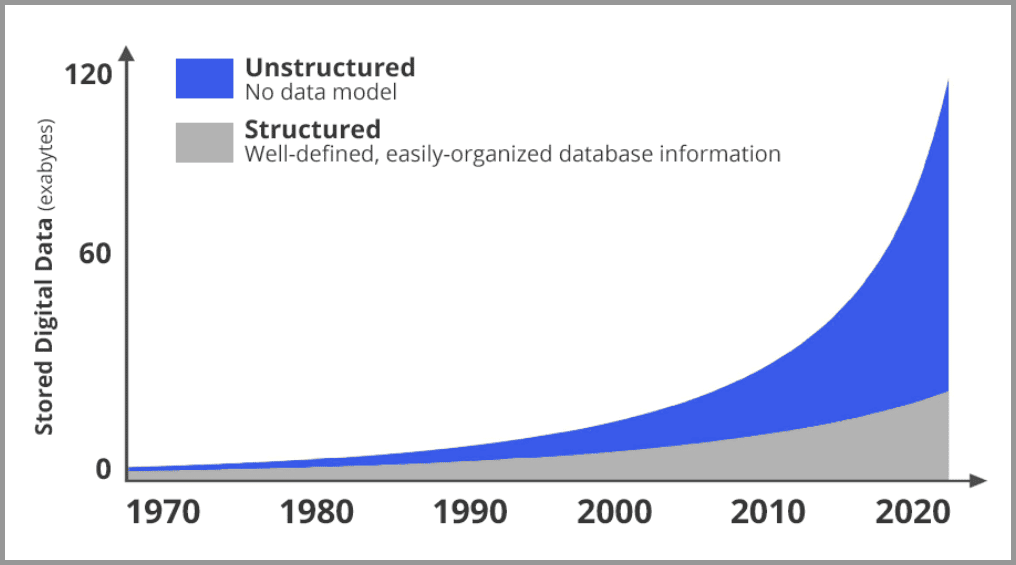
图片和视频数据在飞速增长
而在计算机视觉出现之前,图像对于计算机来说是黑盒的状态。
一张图片对于机器只是一个文件。机器并不知道图片里的内容到底是什么,只知道这张图片是什么尺寸,多少MB,什么格式的。

CV之前,机器智能看到文件属性,看不懂图片内容
如果计算机、人工智能想要在现实世界发挥重要作用,就必须看懂图片!这就是计算机视觉要解决的问题。
什么是计算机视觉 – CV?
计算机视觉是人工智能的一个重要分支,它要解决的问题就是:看懂图像里的内容。
比如:
图片里的宠物是猫还是狗?
图片里的人是老张还是老王?
这张照片里,桌子上放了哪些物品?

CV让机器可以看懂图片里的内容
计算机视觉的原理是什么?
目前主流的基于深度学习的机器视觉方法,其原理跟人类大脑工作的原理比较相似。
人类的视觉原理如下:
从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。

人类大脑看图的原理
机器的方法也是类似:构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类。

CV的原理和人类视觉的原理类似
计算机视觉的2大挑战
对于人类来说看懂图片是一件很简单的事情,但是对于机器来说这是一个非常难的事情,说 2 个典型的难点:
特征难以提取
同一只猫在不同的角度,不同的光线,不同的动作下。像素差异是非常大的。就算是同一张照片,旋转90度后,其像素差异也非常大!
所以图片里的内容相似甚至相同,但是在像素层面,其变化会非常大。这对于特征提取是一大挑战。
需要计算的数据量巨大
手机上随便拍一张照片就是1000*2000像素的。每个像素 RGB 3个参数,一共有1000 X 2000 X 3=6,000,000。随便一张照片就要处理 600万 个参数,再算算现在越来越流行的 4K 视频。就知道这个计算量级有多恐怖了。

计算机视觉的2大挑战
CNN 解决了上面的两大难题
CNN 属于深度学习的范畴,它很好的解决了上面所说的2大难点:
CNN 可以有效的提取图像里的特征
CNN 可以将海量的数据(不影响特征提取的前提下)进行有效的降维,大大减少了对算力的要求
CNN 的具体原理这里不做具体说明,感兴趣的可以看看《一文看懂卷积神经网络-CNN(基本原理+独特价值+实际应用)》
计算机视觉的 8 大任务

CV的8大任务
图像分类
图像分类是计算机视觉中重要的基础问题。后面提到的其他任务也是以它为基础的。
举几个典型的例子:人脸识别、图片鉴黄、相册根据人物自动分类等。

计算机视觉图像分类
目标检测
目标检测任务的目标是给定一张图像或是一个视频帧,让计算机找出其中所有目标的位置,并给出每个目标的具体类别。

计算机视觉目标检测
语义分割
它将整个图像分成像素组,然后对像素组进行标记和分类。语义分割试图在语义上理解图像中每个像素是什么(人、车、狗、树…)。
如下图,除了识别人、道路、汽车、树木等之外,我们还必须确定每个物体的边界。

计算机视觉语义分割
实例分割
除了语义分割之外,实例分割将不同类型的实例进行分类,比如用 5 种不同颜色来标记 5 辆汽车。我们会看到多个重叠物体和不同背景的复杂景象,我们不仅需要将这些不同的对象进行分类,而且还要确定对象的边界、差异和彼此之间的关系!

计算机视觉实例分割
视频分类
与图像分类不同的是,分类的对象不再是静止的图像,而是一个由多帧图像构成的、包含语音数据、包含运动信息等的视频对象,因此理解视频需要获得更多的上下文信息,不仅要理解每帧图像是什么、包含什么,还需要结合不同帧,知道上下文的关联信息。

计算机视觉视频分类
人体关键点检测
体关键点检测,通过人体关键节点的组合和追踪来识别人的运动和行为,对于描述人体姿态,预测人体行为至关重要。
在 Xbox 中就有利用到这个技术。

计算机视觉人体关键点检测
场景文字识别
很多照片中都有一些文字信息,这对理解图像有重要的作用。
场景文字识别是在图像背景复杂、分辨率低下、字体多样、分布随意等情况下,将图像信息转化为文字序列的过程。
停车场、收费站的车牌识别就是典型的应用场景。

计算机视觉场景文字识别
目标跟踪
目标跟踪,是指在特定场景跟踪某一个或多个特定感兴趣对象的过程。传统的应用就是视频和真实世界的交互,在检测到初始对象之后进行观察。
无人驾驶里就会用到这个技术。
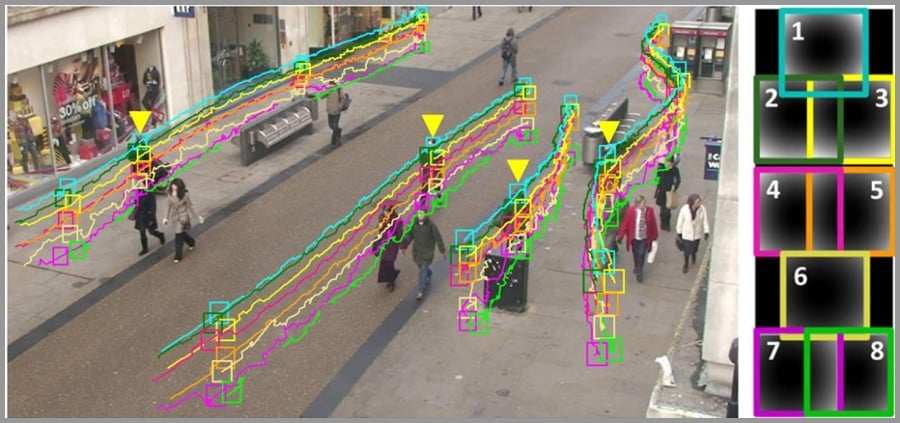
计算机视觉目标跟踪
计算机视觉在日常生活中的应用场景
计算机视觉的应用场景非常广泛,下面列举几个生活中常见的应用场景。
门禁、支付宝上的人脸识别
停车场、收费站的车牌识别
上传图片或视频到网站时的风险识别
抖音上的各种道具(需要先识别出人脸的位置)

计算机视觉在日常生活中的应用场景
这里需要说明一下,条形码和二维码的扫描不算是计算机视觉。
这种对图像的识别,还是基于固定规则的,并不需要处理复杂的图像,完全用不到 AI 技术。
百科介绍
搜狗百科(详情)
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取‘信息’的人工智能系统。这里所 指的信息指Shannon定义的,可以用来帮助做一个“决定”的信息。因为感知可以看作是从感官信号中提 取信息,所以计算机视觉也可以看作是研究如何使人工系统从图像或多维数据中“感知”的科学。
维基百科(详情)
计算机视觉是一个跨学科的科学领域,涉及如何制作计算机以从数字图像或视频中获得高层次的理解。从工程的角度来看,它寻求自动化人类视觉系统可以完成的任务。
计算机视觉任务包括用于获取,处理,分析和理解数字图像的方法,以及从现实世界中提取高维数据以便例如以决策的形式产生数字或符号信息。
在这种情况下理解意味着将视觉图像(视网膜的输入)转换为可以与其他思维过程交互并引出适当行动的世界描述。这种图像理解可以看作是利用几何学,物理学,统计学和学习理论构建的模型从图像数据中解开符号信息。
作为一门科学学科,计算机视觉关注从图像中提取信息的人工系统背后的理论。图像数据可以采用多种形式,例如视频序列,来自多个相机的视图或来自医学扫描仪的多维数据。作为一门技术学科,计算机视觉试图将其理论和模型应用于计算机视觉系统的构建。 计算机视觉的子域包括场景重建,事件检测,视频跟踪,对象识别,3D姿态估计,学习,索引,运动估计和图像恢复。
扩展阅读
开拓视野
实践类
初学者的 CV Python教程-OpenCV(第一部分)(需要科学上网)
初学者的 CV Python教程-OpenCV(第二部分)(需要科学上网)
从三大案例,看如何用 CV 模型解决非视觉问题
使用Google Colab构建一个图像分类模型,10分钟搞定!
应用类