KTransformers:让DeepSeek加速27倍的国产推理框架

在AI技术飞速发展的今天,大语言模型(LLM)的应用越来越广泛。然而,本地运行这些模型,尤其是像DeepSeek-R1这样的大模型,往往需要高性能的硬件支持,这让许多开发者和研究人员望而却步。
因此,KTransformers应运而生了,KTransformers是一款由清华大学 MADSys 和 Approaching.AI 专为优化大模型本地推理体验而设计的开源框架,它支持在单卡24GB VRAM的GPU上运行满血版的DeepSeek-R1,较llama.cpp而言,预填充阶段性能提升高达27.79倍!其主要的优化策略有:
混合推理:KTransformers 框架采用 CPU 和 GPU 混合推理技术。计算密集型操作被卸载到 GPU,而其他操作则由 CPU 处理。这种分工协作的方式能够充分利用硬件资源,提高效率。
专家选择策略:框架使用了一种基于离线剖析结果的专家选择策略。在推理过程中,选择较少的专家参与计算,在不影响输出质量的前提下,有效地减少了内存占用。
Intel AMX 优化:框架中使用了 AMX 加速内核和缓存友好的内存布局。这些优化措施显著提升了性能,并减少了内存开销。
高效内存管理:为了避免 NUMA 节点之间的数据传输成本,框架将关键矩阵复制到两个 NUMA 节点,从而加快预填充和解码过程。虽然这种方法增加了内存消耗,但显著提升了性能
什么是KTransformers?
KTransformers是一个基于Python的开源框架,专注于优化大模型的本地推理体验。它通过先进的内核优化和灵活的硬件配置策略,让开发者能够在有限的资源下实现高效的模型推理,并提供了与 Transformers 兼容的接口、符合 OpenAI 和 Ollama 标准的 RESTful API。
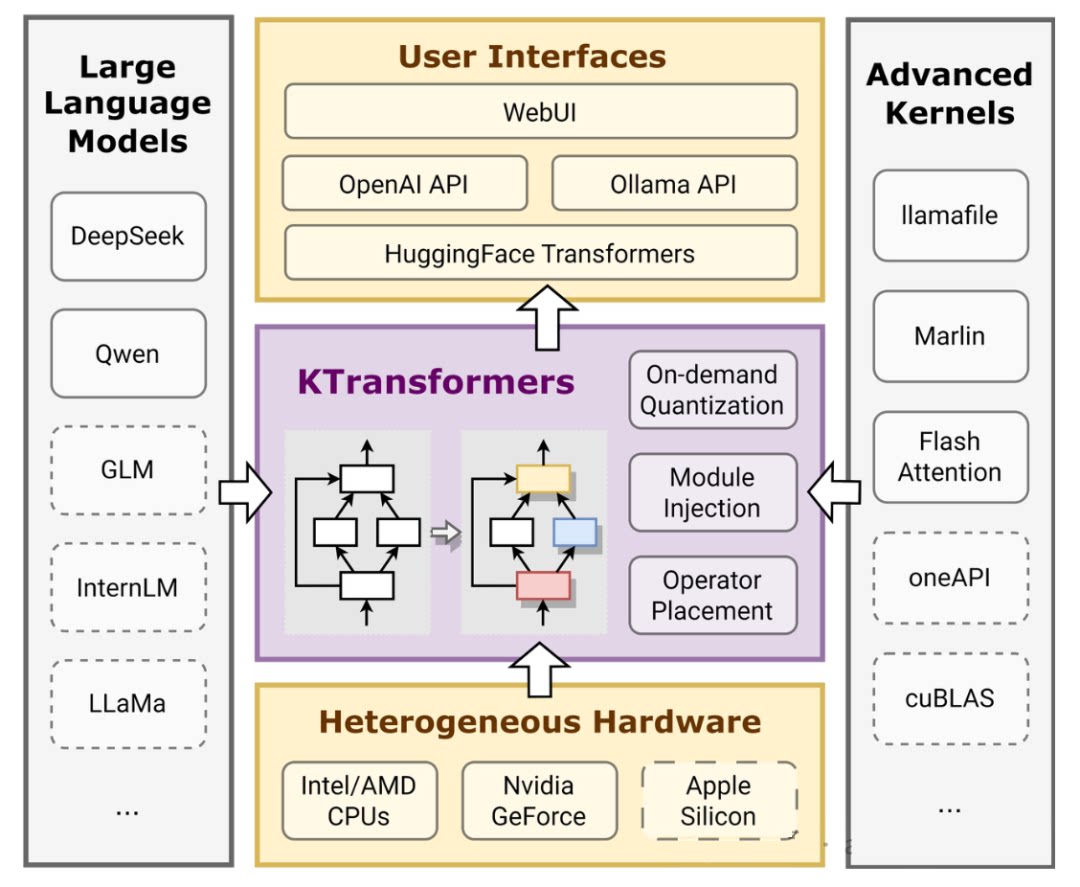
无论是单GPU、多GPU,还是CPU/GPU混合推理,KTransformers都能提供卓越的性能表现。此外,它还支持多种量化方法(如Q2K、Q3K、Q5K等),能够在不显著影响模型精度的情况下,大幅降低内存占用。
KTransformers 的性能优化基本囊括了目前主流的优化手段,包括:
内核优化:通过注入优化的内核(如 Llamafile 和 Marlin),替换 PyTorch 原生模块,从而提高计算效率。这些内核针对特定硬件和数据类型进行了深度优化。
量化技术:支持模型量化,将模型权重从高精度浮点数转换为低精度整数,减少模型大小和计算量,同时保持模型性能。
并行策略:采用先进的并行策略,将计算任务分配到多个设备并行执行,加速推理过程。
稀疏注意力:面对长文本输入,采用稀疏注意力机制,减少计算复杂度,提高推理速度。
CPU/GPU 卸载:支持将计算任务在 CPU 和 GPU 之间灵活分配,充分利用不同硬件的优势。
动态负载均衡:可以根据硬件负载情况动态调整任务分配,实现负载均衡,提高整体性能。
注入框架:提供了一个灵活的注入框架,允许用户通过 YAML 配置文件定义优化规则,将指定模块替换为优化版本。
通过这些优化,也换来了不错的应用效果:
DeepSeek V3/R1:在单张 24GB 显存的 GPU 上,KTransformers 能够以高达 286.55 tokens/s 的速度运行 DeepSeek-Coder-V3/R1 模型,相比 llama.cpp 提升了 27.79 倍。
InternLM2.5-7B-Chat-1M:KTransformers 支持在 24GB 显存和 150GB 内存的电脑上bf16精度运行 InternLM2.5-7B-Chat-1M 模型,实现 1M 上下文的推理任务。它在 1M “大海捞针” 测试中达到了 92.88%的成功率,在 128K的测试中达到了 100%。
KTransformers核心功能
支持DeepSeek-R1/V3本地运行
KTransformers支持在单卡24GB VRAM的GPU上运行DeepSeek-R1/V3的Q4_K_M版本,性能表现如下:
Prefill Speed(tokens/s):54.21(单节点)→ 74.362(双节点)→ 286.55(优化后)。
Decode Speed(tokens/s):8.73(单节点)→ 11.26(双节点)→ 13.69(优化后)。
相比llama.cpp,KTransformers的Prefill速度提升高达27.79倍,Decode速度提升3.03倍!
支持长上下文推理
KTransformers能够在单卡24GB GPU上支持128K甚至1M的长上下文推理,速度比llama.cpp快10倍以上,同时保持100%的推理精度。
多GPU和异构计算支持
KTransformers不仅支持多GPU并行推理,还支持CPU/GPU混合推理,充分利用硬件资源,提升推理效率。
灵活的配置和优化
用户可以通过简单的YAML配置文件,灵活地调整模型的优化策略,例如选择不同的量化方法或替换特定的模块。
丰富的API和教程
KTransformers提供了RESTful API和详细的教程文档,方便开发者快速上手。
如何使用KTransformers?
使用KTransformers非常简单,以下是基本步骤:
安装依赖
pip install ktransformers加载模型
from transformers import AutoModelForCausalLM
import torch
with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)优化和加载模型
from ktransformers import optimize_and_load_gguf
optimize_and_load_gguf(model, optimize_rule_path, gguf_path, config)生成文本
generated = prefill_and_generate(model, tokenizer, input_tensor.cuda(), max_new_tokens=1000)性能对比:KTransformers vs llama.cpp
从上表可以看出,KTransformers在性能上远超llama.cpp,尤其是在Prefill阶段,速度提升了27.79倍!
KTransformers的适用场景
本地开发和测试
如果您希望在本地快速开发和测试大模型,KTransformers是一个理想的选择。
资源受限的环境
对于硬件资源有限的开发者,KTransformers可以通过优化和量化,让模型在有限的资源下运行得更好。
高性能推理需求
如果您需要在本地实现高性能的模型推理,KTransformers的多GPU和异构计算支持能够满足您的需求。
最后,附上KTransformers开源地址:https//github.com/kvcache-ai/ktransformers