K邻近算法(k-nearest neighbors | KNN)
什么是 K邻近算法?
KNN算法非常简单且非常有效。KNN的模型表示是整个训练数据集。简单吧?
通过搜索K个最相似的实例(邻居)的整个训练集并总结那些K个实例的输出变量,对新数据点进行预测。对于回归问题,这可能是平均输出变量,对于分类问题,这可能是模式(或最常见)类值。
诀窍在于如何确定数据实例之间的相似性。如果您的属性具有相同的比例(例如,以英寸为单位),则最简单的技术是使用欧几里德距离,您可以根据每个输入变量之间的差异直接计算该数字。
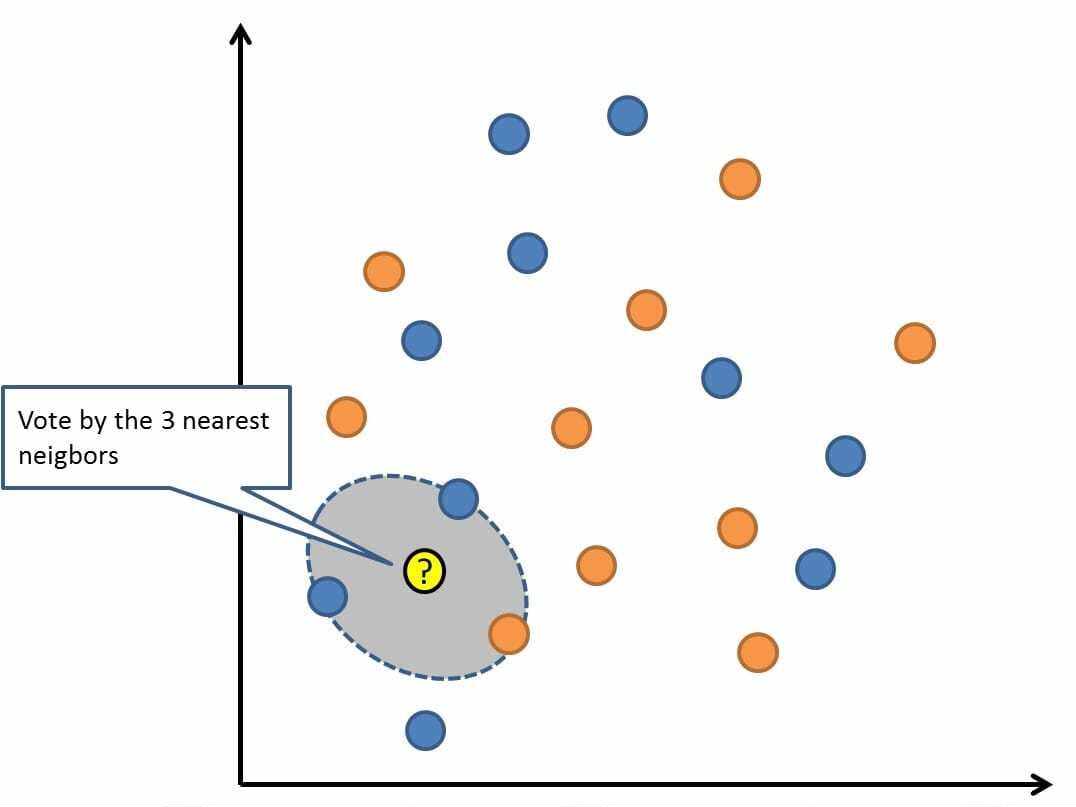
K邻近算法
KNN可能需要大量内存或空间来存储所有数据,但仅在需要预测时才进行计算(或学习),及时。您还可以随着时间的推移更新和策划您的训练实例,以保持预测准确。
距离或接近度的概念可以在非常高的维度(许多输入变量)中分解,这会对算法在您的问题上的性能产生负面影响。这被称为维度的诅咒。它建议您仅使用与预测输出变量最相关的输入变量。
K邻近算法的优缺点
优点
理论成熟,思想简单,既可以用来做分类也可以用来做回归;
可用于非线性分类;
训练时间复杂度为O(n);
对数据没有假设,准确度高,对outlier不敏感;
KNN是一种在线技术,新数据可以直接加入数据集而不必进行重新训练;
KNN理论简单,容易实现;
缺点
样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)效果差;
需要大量内存;
对于样本容量大的数据集计算量比较大(体现在距离计算上);
样本不平衡时,预测偏差比较大。如:某一类的样本比较少,而其它类样本比较多;
KNN每一次分类都会重新进行一次全局运算;
k值大小的选择没有理论选择最优,往往是结合K-折交叉验证得到最优k值选择;
百科介绍
百度百科(详情)
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
维基百科(详情)
在模式识别中,k-最近邻算法(k -NN)是用于分类和回归的非参数方法。在这两种情况下,输入都包含特征空间中最近的k个训练样例。输出取决于k -NN是用于分类还是回归:
在k-NN分类中,输出是类成员资格。对象通过其邻居的多个投票进行分类,其中对象被分配给其k个最近邻居中最常见的类(k是正整数,通常是小整数)。如果k = 1,则简单地将对象分配给该单个最近邻居的类。
在k-NN回归中,输出是对象的属性值。该值是其k个最近邻居的值的平均值。
k -NN是一种基于实例的学习或懒惰学习,其中函数仅在本地近似,并且所有计算都推迟到分类。该ķ -NN算法是最简单的所有中机器学习算法。