特征工程 | Feature Engineering

特征工程是机器学习工作流程中重要的组成部分,他是将原始数据「翻译」成模型可理解的形式。
本文将介绍特征工程的基本概念、重要性和性能评估的4个步骤。
特征工程的重要性
大家都听过美国计算机科学家 Peter Norvig 的2句经典名言:
基于大量数据的简单模型优于基于少量数据的复杂模型。
这句说明了数据量的重要性。
更多的数据优于聪明的算法,而好的数据优于多的数据。
这句则是说的特征工程的重要性。
所以,如何基于给定数据来发挥更大的数据价值就是特征工程要做的事情。
在16年的一项调查中发现,数据科学家的工作中,有80%的时间都在获取、清洗和组织数据。构造机器学习流水线的时间不到20%。详情如下:
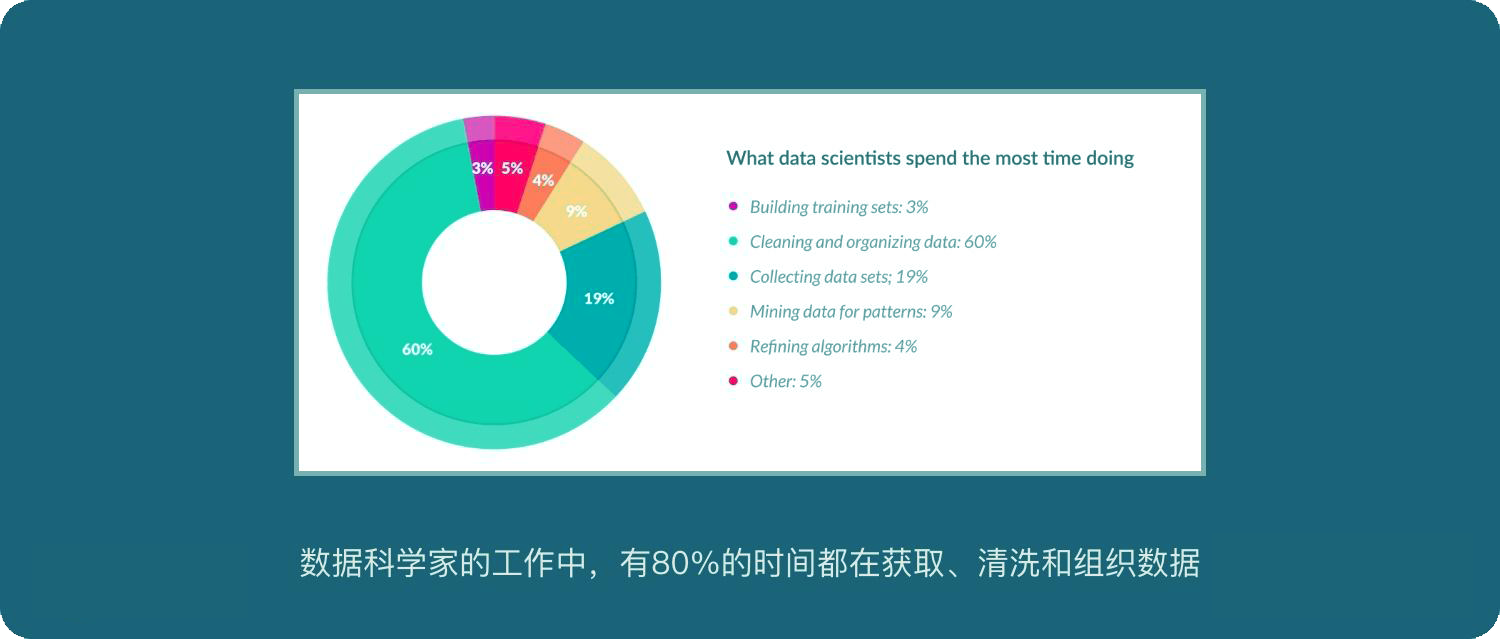
数据科学家的工作中,有80%的时间都在获取、清洗和组织数据
设置训练集:3%
清洗和组织数据:60%
收集数据集:19%
挖掘数据模式:9%
调整算法:5%
其他:4%
PS:数据清洗和组织数据也是数据科学家「最讨厌」的工作。感兴趣的可以看这篇原始的文章:
数据来源:《Data Scientists Spend Most of Their Time Cleaning Data》
什么是特征工程
我们先来看看特征工程在机器学习流程中的位置:

特征工程在机器学习流程中的位置
从上图可以看出,特征工程处在原始数据和特征之间。他的任务就是将原始数据「翻译」成特征的过程。
特征:是原始数据的数值表达方式,是机器学习算法模型可以直接使用的表达方式。
特征工程是一个过程,这个过程将数据转换为能更好的表示业务逻辑的特征,从而提高机器学习的性能。
这么说可能不太好理解。其实特征工程跟做饭很像:
我们将食材购买回来,经过清洗、切菜,然后开始根据自己的喜好进行烹饪,做出美味的饭菜。

特征工程跟做饭很像
上面的例子中:
食材就好像原始数据
清洗、切菜、烹饪的过程就好像特征工程
最后做出来的美味饭菜就是特征
人类是需要吃加工过的食物才行,这样更安全也更美味。机器算法模型也是类似,原始数据不能直接喂给模型,也需要对数据进行清洗、组织、转换。最后才能得到模型可以消化的特征。
除了将原始数据转化为特征之外,还有2个容易被忽视的重点:
重点1:更好的表示业务逻辑
特征工程可以说是业务逻辑的一种数学表达。
我们使用机器学习的目的是为了解决业务中的特定问题。相同的原始数据有很多种转换为特征的方式,我们需要选择那些能够「更好的表示业务逻辑」,从而更好的解决问题。而不是那些更简单的方法。
重点2:提高机器学习性能
性能意味着更短时间和更低成本,哪怕相同的模型,也会因为特征工程的不同而性能不同。所以我们需要选择那些可以发挥更好性能的特征工程。
评估特征工程性能的4个步骤
特征工程的业务评估很重要,但是方法五花八门,不同业务有不同的评估方法。
这里只介绍性能的评估方式,相对通用一些。

评估特征工程性能的4个步骤
在应用任何特征工程之前,得到机器学习模型的基准性能
应用一种或多种特征工程
对于每种特征工程,获取一个性能指标,并与基准性能进行对比
如果性能的增量大于某个阈值,则认为特征工程是有益的,并在机器学习流水线上应用
例如:基准性能的准确率是40%,应用某种特征工程后,准确率提升到76%,那么改变就是90%。
(76%-40%)/ 40%=90%
总结
特征工程是机器学习流程里最花时间的工作,也是最重要的工作内容之一。
特征工程定义:是一个过程,这个过程将数据转换为能更好的表示业务逻辑的特征,从而提高机器学习的性能。
特征工程容易被忽略的2个重点:
更好的表示业务逻辑
提高机器学习性能
特征工程性能评估的4个步骤:
在应用任何特征工程之前,得到机器学习模型的基准性能
应用一种或多种特征工程
对于每种特征工程,获取一个性能指标,并与基准性能进行对比
如果性能的增量大于某个阈值,则认为特征工程是有益的,并在机器学习流水线上应用