无监督学习 (Unsupervised learning | UL)
什么是无监督学习?

无监督学习是机器学习领域内的一种学习方式。本文将给大家解释他的基本概念,告诉大家无监督学习可以用用到哪些具体场景中。
最后给大家举例说明2类无监督学习的思维:聚类、降维。以及具体的4种算法。
无监督学习是机器学习中的一种训练方式/学习方式:
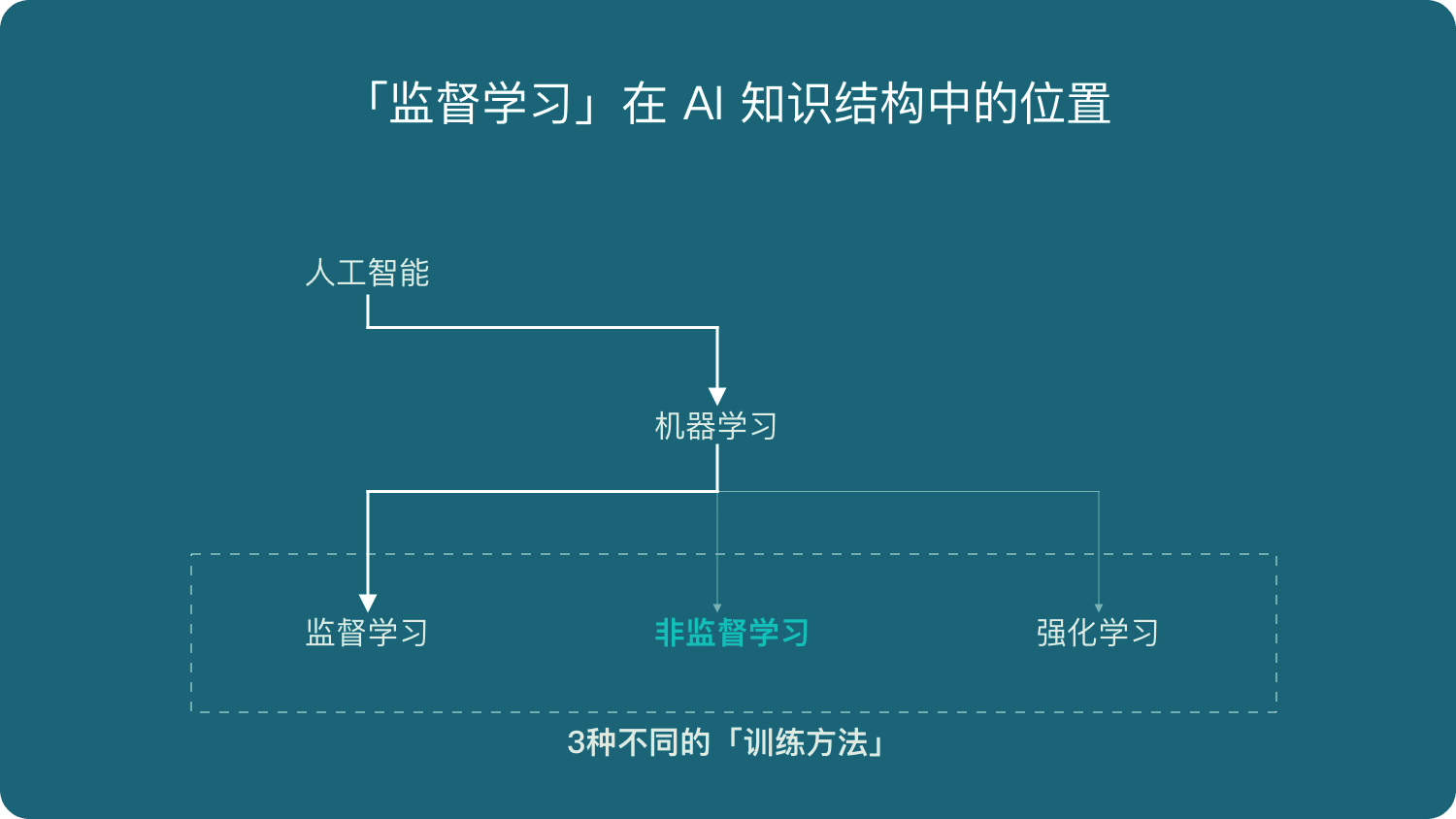
下面通过跟监督学习的对比来理解无监督学习:
监督学习是一种目的明确的训练方式,你知道得到的是什么;而无监督学习则是没有明确目的的训练方式,你无法提前知道结果是什么。
监督学习需要给数据打标签;而无监督学习不需要给数据打标签。
监督学习由于目标明确,所以可以衡量效果;而无监督学习几乎无法量化效果如何

简单总结一下:
无监督学习是一种机器学习的训练方式,它本质上是一个统计手段,在没有标签的数据里可以发现潜在的一些结构的一种训练方式。
它主要具备3个特点:
无监督学习没有明确的目的
无监督学习不需要给数据打标签
无监督学习无法量化效果
这么解释很难理解,下面用一些具体案例来告诉大家无监督学习的一些实际应用场景,通过这些实际场景,大家就能了解无监督学习的价值。
无监督学习的使用场景
案例1:发现异常
有很多违法行为都需要”洗钱”,这些洗钱行为跟普通用户的行为是不一样的,到底哪里不一样?
如果通过人为去分析是一件成本很高很复杂的事情,我们可以通过这些行为的特征对用户进行分类,就更容易找到那些行为异常的用户,然后再深入分析他们的行为到底哪里不一样,是否属于违法洗钱的范畴。
通过无监督学习,我们可以快速把行为进行分类,虽然我们不知道这些分类意味着什么,但是通过这种分类,可以快速排出正常的用户,更有针对性的对异常行为进行深入分析。
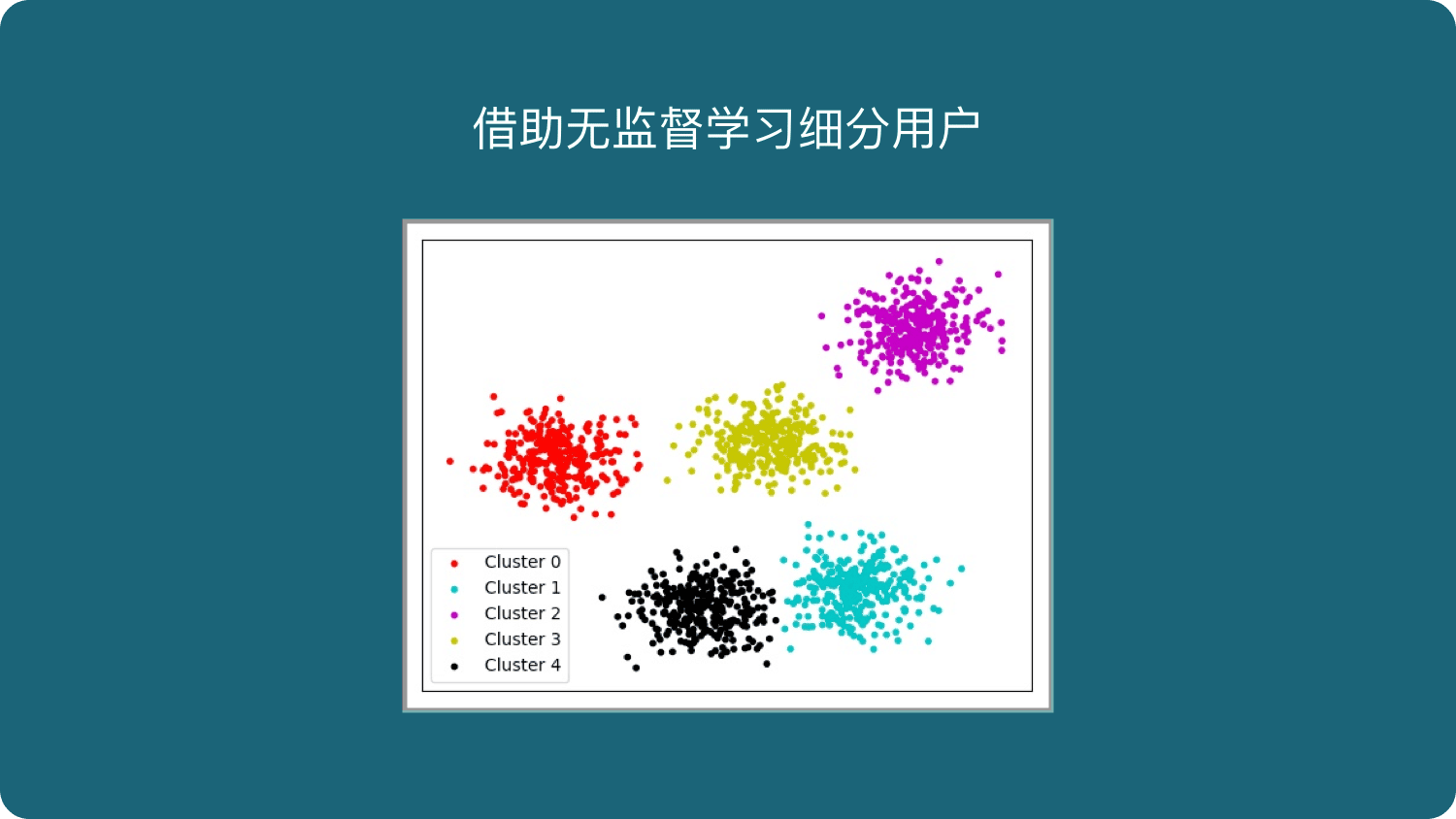
案例2:用户细分
这个对于广告平台很有意义,我们不仅把用户按照性别、年龄、地理位置等维度进行用户细分,还可以通过用户行为对用户进行分类。
通过很多维度的用户细分,广告投放可以更有针对性,效果也会更好。

案例3:推荐系统
大家都听过”啤酒+尿不湿”的故事,这个故事就是根据用户的购买行为来推荐相关的商品的一个例子。
比如大家在淘宝、天猫、京东上逛的时候,总会根据你的浏览行为推荐一些相关的商品,有些商品就是无监督学习通过聚类来推荐出来的。系统会发现一些购买行为相似的用户,推荐这类用户最”喜欢”的商品。
常见的2类无监督学习算法
常见的2类算法是:聚类、降维

聚类:简单说就是一种自动分类的方法,在监督学习中,你很清楚每一个分类是什么,但是聚类则不是,你并不清楚聚类后的几个分类每个代表什么意思。
降维:降维看上去很像压缩。这是为了在尽可能保存相关的结构的同时降低数据的复杂度。
「聚类算法」K均值聚类
K均值聚类就是制定分组的数量为K,自动进行分组。
K 均值聚类的步骤如下:
定义 K 个重心。一开始这些重心是随机的(也有一些更加有效的用于初始化重心的算法)
寻找最近的重心并且更新聚类分配。将每个数据点都分配给这 K 个聚类中的一个。每个数据点都被分配给离它们最近的重心的聚类。这里的「接近程度」的度量是一个超参数——通常是欧几里得距离(Euclidean distance)。
将重心移动到它们的聚类的中心。每个聚类的重心的新位置是通过计算该聚类中所有数据点的平均位置得到的。
重复第 2 和 3 步,直到每次迭代时重心的位置不再显著变化(即直到该算法收敛)。
其过程如下面的动图:
 「聚类算法」层次聚类
「聚类算法」层次聚类
如果你不知道应该分为几类,那么层次聚类就比较适合了。层次聚类会构建一个多层嵌套的分类,类似一个树状结构。
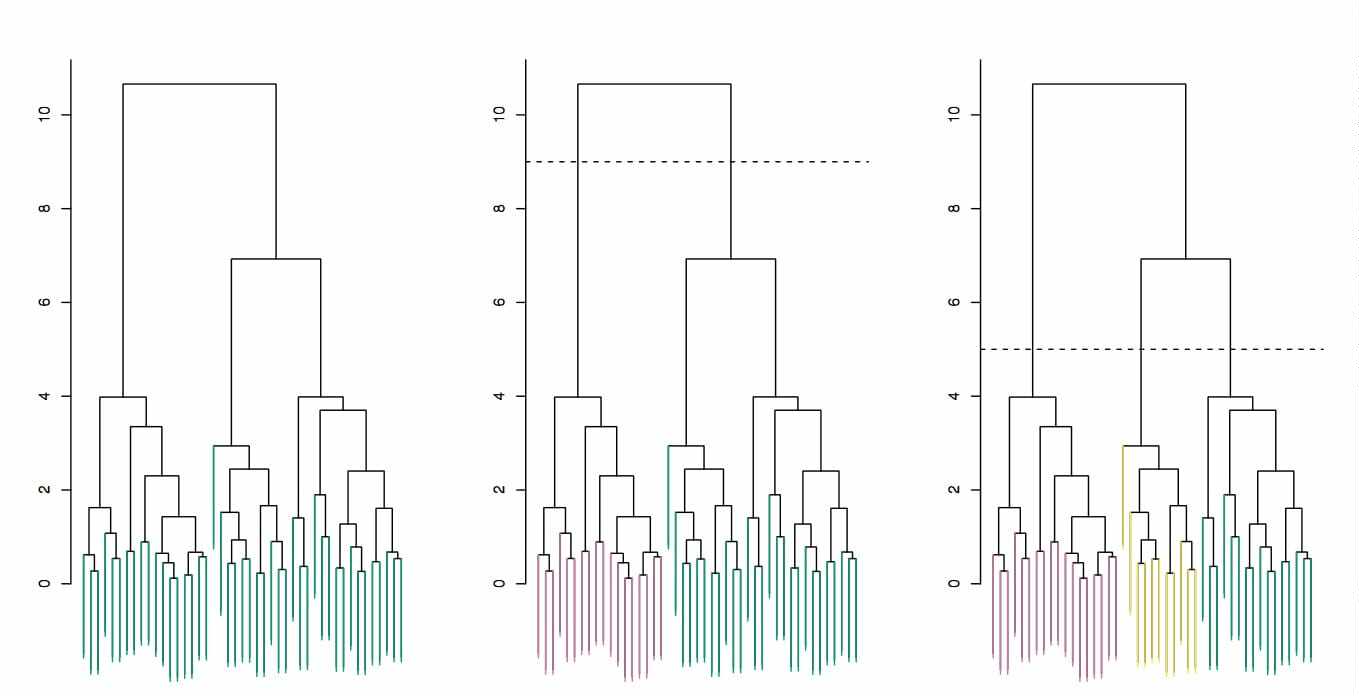
层次聚类的步骤如下:
首先从 N 个聚类开始,每个数据点一个聚类。
将彼此靠得最近的两个聚类融合为一个。现在你有 N-1 个聚类。
重新计算这些聚类之间的距离。
重复第 2 和 3 步,直到你得到包含 N 个数据点的一个聚类。
选择一个聚类数量,然后在这个树状图中划一条水平线。
「降维算法」主成分分析 – PCA
主成分分析是把多指标转化为少数几个综合指标。
主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。
变换的步骤:
第二步计算协方差矩阵S(或C)的特征向量 e1,e2,…,eN和特征值 , t = 1,2,…,N
第三步投影数据到特征向量张成的空间之中。利用下面公式,其中BV值是原样本中对应维度的值。
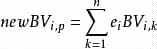
「降维算法」奇异值分解 – SVD
奇异值分解(Singular Value Decomposition)是线性代数中一种重要的矩阵分解,奇异值分解则是特征分解在任意矩阵上的推广。在信号处理、统计学等领域有重要应用。
了解更多奇异值分解的信息,可以查看维基百科
生成模型GAN
无监督学习的最简单目标是训练算法生成自己的数据实例,但是模型不应该简单地重现之前训练的数据,否则就是简单的记忆行为。
它必须是建立一个从数据中的基础类模型。不是生成特定的马或彩虹照片,而是生成马和彩虹的图片集;不是来自特定发言者的特定话语,而是说出话语的一般分布。
生成模型的指导原则是,能够构建一个令人信服的数据示例是理解它的最有力证据。正如物理学家理查德·费曼所说:“我不能创造的东西,我就不能了解”(What I cannot create, I do not understand.)。
对于图像来说,迄今为止最成功的生成模型是生成对抗网络(GAN)。它由两个网络组成:一个生成器和一个鉴别器,分别负责伪造图片和识别真假。

生成器产生图像的目的是诱使鉴别者相信它们是真实的,同时,鉴别者会因为发现假图片而获得奖励。
GAN开始生成的图像是杂乱的和随机的,在许多次迭代中被细化,形成更加逼真的图像,甚至无法与真实照片区别开来。最近英伟达的GauGAN还能根据用户草图生成图片。
百科介绍
百度百科(详情)
现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
维基百科(详情)
无监督学习是机器学习的一个分支,它从未经标记,分类或分类的测试数据中学习。无监督学习不是响应反馈,而是根据每个新数据中是否存在这种共性来识别数据中的共性并做出反应。替代方案包括监督学习和强化学习。 无监督学习的中心的应用是在领域密度估计在统计,[1]虽然无监督学习包括许多涉及总结和解释数据的特征的其他结构域。