逻辑回归 | Logistic regression
什么是逻辑回归?

本文将通俗易懂的介绍逻辑回归的基本概念、优缺点和实际应用的案例。同时会跟线性回归做一些比较,让大家能够有效的区分 2 种不同的算法。
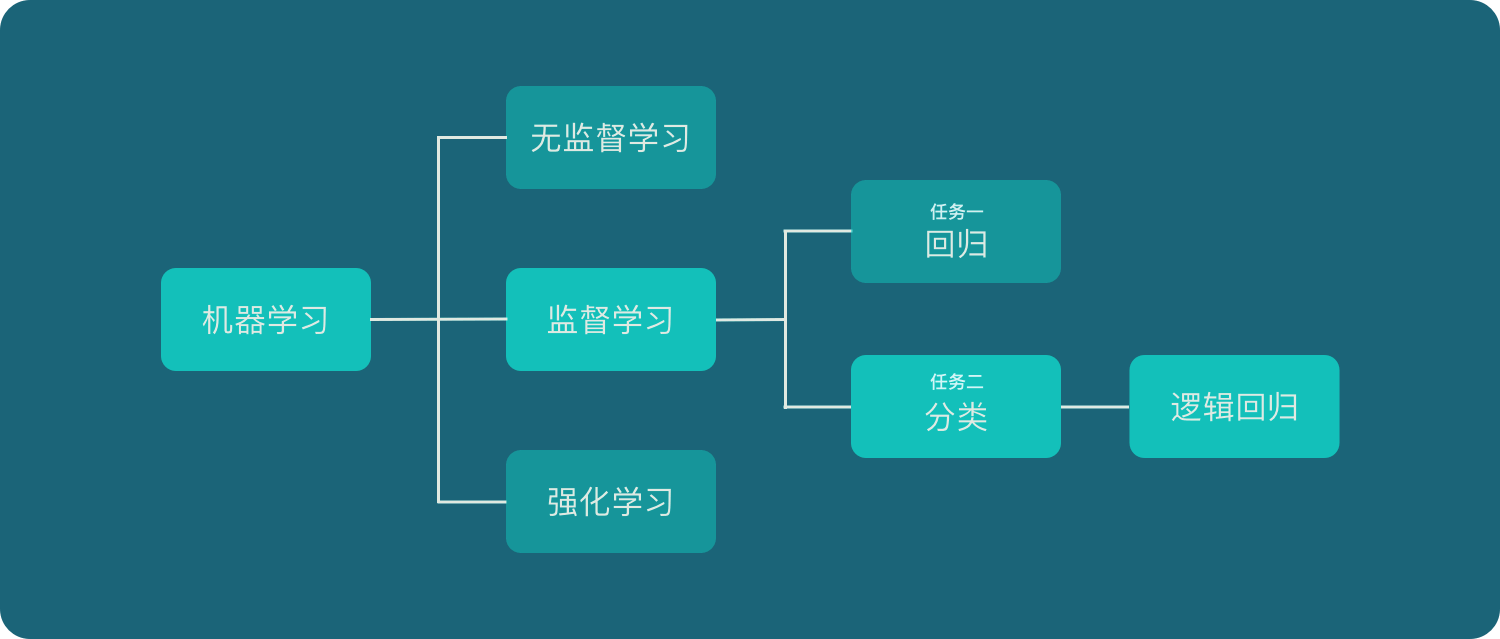
逻辑回归的位置如上图所示,它属于机器学习 – 监督学习 – 分类 – 逻辑回归。
扩展阅读:
《一文看懂机器学习!(3种学习方法+7个实操步骤+15种常见算法)》
逻辑回归(Logistic Regression)主要解决二分类问题,用来表示某件事情发生的可能性。
 什么是逻辑回归
什么是逻辑回归
比如:
一封邮件是垃圾邮件的可能性(是、不是)
你购买一件商品的可能性(买、不买)
广告被点击的可能性(点、不点)
逻辑回归的优缺点
优点:
实现简单,广泛的应用于工业问题上;
分类时计算量非常小,速度很快,存储资源低;
便利的观测样本概率分数;
对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题;
计算代价不高,易于理解和实现;
缺点:
当特征空间很大时,逻辑回归的性能不是很好;
容易欠拟合,一般准确度不太高
不能很好地处理大量多类特征或变量;
只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
对于非线性特征,需要进行转换;
逻辑回归 VS 线性回归
线性回归和逻辑回归是 2 种经典的算法。经常被拿来做比较,下面整理了一些两者的区别:
 线性回归和逻辑回归的区别
线性回归和逻辑回归的区别
线性回归只能用于回归问题,逻辑回归虽然名字叫回归,但是更多用于分类问题(关于回归和分类的区别可以看看这篇文章《一文看懂监督学习(基本概念+4步流程+9个典型算法)》)
线性回归要求因变量是连续性数值变量,而逻辑回归要求因变量是离散的变量
线性回归要求自变量和因变量呈线性关系,而逻辑回归不要求自变量和因变量呈线性关系
线性回归可以直观的表达自变量和因变量之间的关系,逻辑回归则无法表达变量之间的关系
注:
自变量:主动操作的变量,可以看做「因变量」的原因
因变量:因为「自变量」的变化而变化,可以看做「自变量」的结果。也是我们想要预测的结果。

自变量、因变量的解释
美团的应用案例
美团会把逻辑回归应用到业务中解决一些实际问题。这里以预测用户对品类的购买偏好为例,该问题可以转换为预测用户在未来某个时间段是否会购买某个品类,如果把会购买标记为1,不会购买标记为0,就转换为一个二分类问题。我们用到的特征包括用户在美团的浏览,购买等历史信息,见下表:

其中提取的特征的时间跨度为30天,标签为2天。生成的训练数据大约在7000万量级(美团一个月有过行为的用户),我们人工把相似的小品类聚合起来,最后有18个较为典型的品类集合。如果用户在给定的时间内购买某一品类集合,就作为正例。有了训练数据后,使用Spark版的LR算法对每个品类训练一个二分类模型,迭代次数设为100次的话模型训练需要40分钟左右,平均每个模型2分钟,测试集上的AUC也大多在0.8以上。训练好的模型会保存下来,用于预测在各个品类上的购买概率。预测的结果则会用于推荐等场景。
由于不同品类之间正负例分布不同,有些品类正负例分布很不均衡,我们还尝试了不同的采样方法,最终目标是提高下单率等线上指标。经过一些参数调优,品类偏好特征为推荐和排序带来了超过1%的下单率提升。
此外,由于LR模型的简单高效,易于实现,可以为后续模型优化提供一个不错的baseline,我们在排序等服务中也使用了LR模型。
百科介绍
百度百科(详情)
逻辑回归是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。
以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。然后通过logistic回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权值可以根据危险因素预测一个人患癌症的可能性。
维基百科(详情)
在统计学中,逻辑模型是一种广泛使用的统计模型,在其基本形式中,使用逻辑函数来模拟二进制 因变量 ; 存在更复杂的扩展。在回归分析中,逻辑回归是估计逻辑模型的参数; 它是二项式回归的一种形式。
在数学上,二元逻辑模型具有一个具有两个可能值的因变量,例如通过/失败,赢/输,活/死或健康/生病; 这些由指示符变量表示,其中两个值标记为“0”和“1”。在逻辑模型中,对数比值(在对数的的可能性),用于标记为“1”的值是一个线性组合的一个或多个自变量(“预测”); 自变量可以是二进制变量(两个类,由指示符变量编码)或连续变量(任何实际值)。